


•
대용량 일괄 처리의 편의를 위해 설계된 프레임워크
•
배치 = 일괄처리
◦
지정한 스케쥴러에 의해 정해진 시간에 맞춰 작업 수행
•
로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리에 필수적인 기능을 제공
스케쥴링 (Scheduling)
•
정해진 일정 또는 주기에 따라 작업을 실행하는 기능
•
주로 주기적으로 실행되는 반복 작업에 사용됨
•
스프링 프레임워크에서는 @Scheduled 애너테이션을 사용하여 메서드에 스케쥴링을 설정하며,
주기적으로 해당 메서드가 실행되도록 예약 가능
•
주로 백그라운드 작업, 일정한 주기로 데이터를 처리하는 작업, 리소스 관리 등에 활용
Batch VS Scheduler
•
Spring Batch
➜ Batch Job을 관리
➜ But, Job을 구동하거나 실행시키는 기능은 지원하고 있지 않음⠀
•
Scheduler
➜ Spring에서 Batch Job을 실행시키기 위해 사용
Ex. Quartz, Scheduler, Jenkin 등⠀
 Batch의 실행을 위해서는 Scheduler와 함께 사용해야 함 !
Ex. Quartz + Batch
Batch의 실행을 위해서는 Scheduler와 함께 사용해야 함 !
Ex. Quartz + Batch
Batch의 실행을 위해서는 Scheduler와 함께 사용해야 함 !
Ex. Quartz + Batch장점
•
유지보수성
➜ 테스트 용이, 추상화, 풍부한 API
➜ 트랜잭션 및 커밋 횟수와 같은 것들을 애플리케이션에 제공하므로, 처리가 어디까지 진행됐는가라든가 실패시 무슨 일을 해야 하는지 관리할 필요 X
•
유연성
➜ JVM을 이용한 이식성
➜ 시스템 간 코드 공유 능력 (POJO 재활용 등)
•
확장성
➜ 과거의 메인프레임 방식이나, 커스텀하게 처리하던 방식은 병렬 처리를 하려면 고려할게 많아 확장성과 안정성이 떨어지는데, 스프링 배치는 단일 처리 / 병력 처리 등이 모두 가능
•
개발 리소스, 지원
➜ 자바, 스프링 프레임워크를 기반
➜ 커뮤니티의 강력한 지원
•
비용
➜ 오픈 소스임
스프링 배치 Application 조건
•
대용량 데이터
➜ 대용량의 데이터를 가져오거나 전달, 계산하는 등의 처리가 가능해야함
•
자동화
➜ 하드웨어적인 문제를 제외하고는 사용자의 개입이 없이 실행되어야 함
•
견고성
➜ 잘못된 데이터를 충돌/중단 없이 처리할 수 있어야 함
•
신뢰성
➜ 무엇이 잘못되었는지를 추적할 수 있어야 함 ( 로깅 / 알림 )
•
성능
➜ 지정한 시간 안에 처리를 완료하거나 동시에 실행되는 다른 어플리케이션을 방해하지 않도록
수행되어야 함
스프링 배치를 사용하는 경우 (일괄 처리가 필요한 경우)
•
대용량의 비즈니스 데이터를 복잡한 작업으로 처리해야 하는 경우
•
특정한 시점에 스케줄러를 통해 자동화된 작업이 필요한 경우
•
대용량 데이터의 포맷을 변경, 유효성 검사 등의 작업을 트랜잭션 안에서 처리 후 기록해야하는 경우
스프링 배치 계층 구조
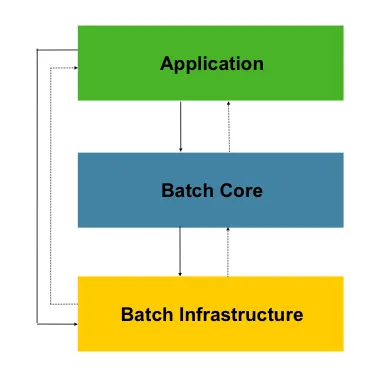
•
Application
◦
Spring Batch를 사용하여 개발자가 작성한 모든 배치 작업과 사용자 정의 코드
•
Batch Core
◦
배치 작업을 시작하고 제어하는 데 필요한 핵심 런타임 클래스를 포함
•
Batch Infrastructure
◦
개발자의 애플리케이션에서 사용하는 일반적인 Reader와 Writer, RetryTemplate과 같은 서비스를
포함
스프링 배치 아키택쳐
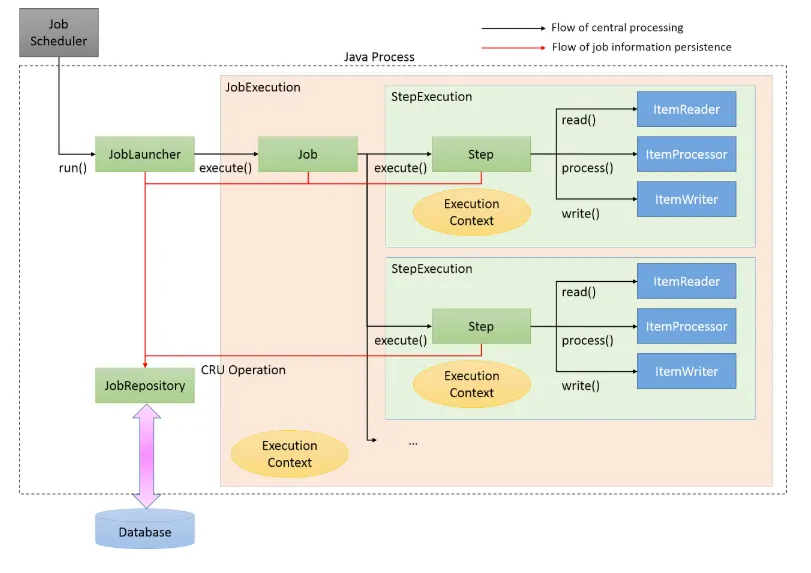
•
Job
◦
배치 처리 과정을 하나의 단위로 만들어 놓은 객체
◦
배치 처리 과정에 있어 전체 계층 최상단에 위치
◦
최소한 1개 이상의 Step을 가져야 함
•
JobInstance
◦
Job의 실행 단위(Job.execute 를 호출하는 역할)
◦
Job을 실행시키게 되면 하나의 Job Instance가 생성
Ex.
1월 1일 실행, 1월 2일 실행을 하게 되면 각각의 JobInstance가 생성되며
1월 1일 실행한 JobInstance가 실패하여 다시 실행을 시키더라도
이 JobInstance는 1월 1일에 대한 데이터만 처리
Plain Text
복사
•
JobParameters
◦
배치 작업이 수행될 때마다 전달되는 Parameter
◦
Job Instance 구별시 사용
◦
String, Double, Long, Date 4가지 형식 지원
Ex. 시작 시간, 데이터를 읽을 범위 등을 지정하여 Batch Job Instance를 생성한다면,
이 때 넘어가는 인자가 JobParameter
Plain Text
복사
•
JobExecution
◦
Job Instance의 실행 시도에 대한 객체
◦
실패하여 재실행 시킨 경우 2번 실행에 대한 JobExecution은 개별로 생김 (동일한 Job Instance)
◦
Job Instance 실행에 대한 상태, 시작시간, 종료시간, 생성시간 등의 정보를 담음
•
Step
◦
Job을 구성하는 독립된 작업 단위
◦
순차적인 단계를 캡슐화함
◦
Job의 실제 일괄 처리를 제어하는 모든 정보를 포함
◦
Tasklet, Chunk의 2가지 기반 존재
▪
여기서 Tasklet을 쓸 것이냐 Chunk를 쓸 것인지를 선택할 수 있음
•
StepExecution
◦
Step 실행 시도에 대한 객체
◦
Step이 실제로 시작될 때만 생성됨
◦
JobExecution에 저장되는 정보 외에 read 수, write 수, commit 수, skip 수 등의 정보들도 저장됨
Job이 여러개의 Step으로 구성되어 있을 경우,
이전 단계의 Step이 실패하면 이후 StepExecution은 생성되지 않음
Plain Text
복사
•
ExecutionContext
◦
Job에서 데이터를 공유할 수 있는 데이터 저장소
◦
Spring Batch에서 제공하는 ExecutionContext는 JobExecutionContext, StepExecutionContext의 2가지 종류. But, 이 두 가지는 지정되는 범위가 다름
▪
JobExecutionContext - Commit 시점에 저장
▪
StepExecutionContext - 실행 사이에 저장
◦
ExecutionContext를 통해 Step 간 Data 공유 가능
◦
Job 실패 시 ExecutionContext를 통한 마지막 실행 값을 재구성 할 수 있음
•
JobRepository
◦
위의 모든 배치 처리 정보를 담고있는 매커니즘
◦
일반적으로 관계형 데이터베이스를 사용하며 스프링 배치 내의 대부분의 주요 컴포넌트가 공유
◦
Job이 실행되면 JobRepository에 JobExecution과 StepExecution을 생성하고,
JobRepository에서 Execution 정보들을 저장하고 조회하며 사용하게 됨
•
JobLauncher
◦
Job과 JobParameters를 사용하여 Job을 실행하는 객체
◦
Job.execute을 호출하는 역할
•
ItemReader
◦
Step(Database) 에서 배치 처리할 Item을 읽어오는 역할
◦
ItemReader에 대한 다양한 인터페이스가 존재하고, 다양한 방법으로 Item을 읽어올 수 있음
•
ItemProcessor
◦
Reader로 읽어온 Item을 데이터를 가공/처리 하는 역할
◦
배치를 처리하는데 필수 요소는 아님
◦
item을 필터 도중 null로 리턴하면, 그 item은 write로 전달되지 못함
(값이 정확히 있는 item들만 write로 전달됨)
•
ItemWriter
◦
Processor로 가공/처리 된 데이터들 (items : List<Item>) 을 Database에 저장하는 역할
◦
처리 결과물에 따라 Insert / Update / Queue 를 사용한다면 Send가 될 수도 있음
◦
ItemWriter에 대한 다양한 인터페이스가 존재
◦
기본적으로 item들은 List 단위로 처리되며, 그 List는 Chunk 단위로 처리됨