


테이블 관련 명령
•
테이블 생성
CREATE TABLE 테이블명 (
컬럼명1 타입 [CONSTRAINT 제약조건이름] 컬럼제약조건,
컬럼명2 타입,
컬럼명3 타입,
...
[CONSTRAINT 제약조건이름] 테이블 제약 조건) 옵션=옵션값;
SQL
복사
•
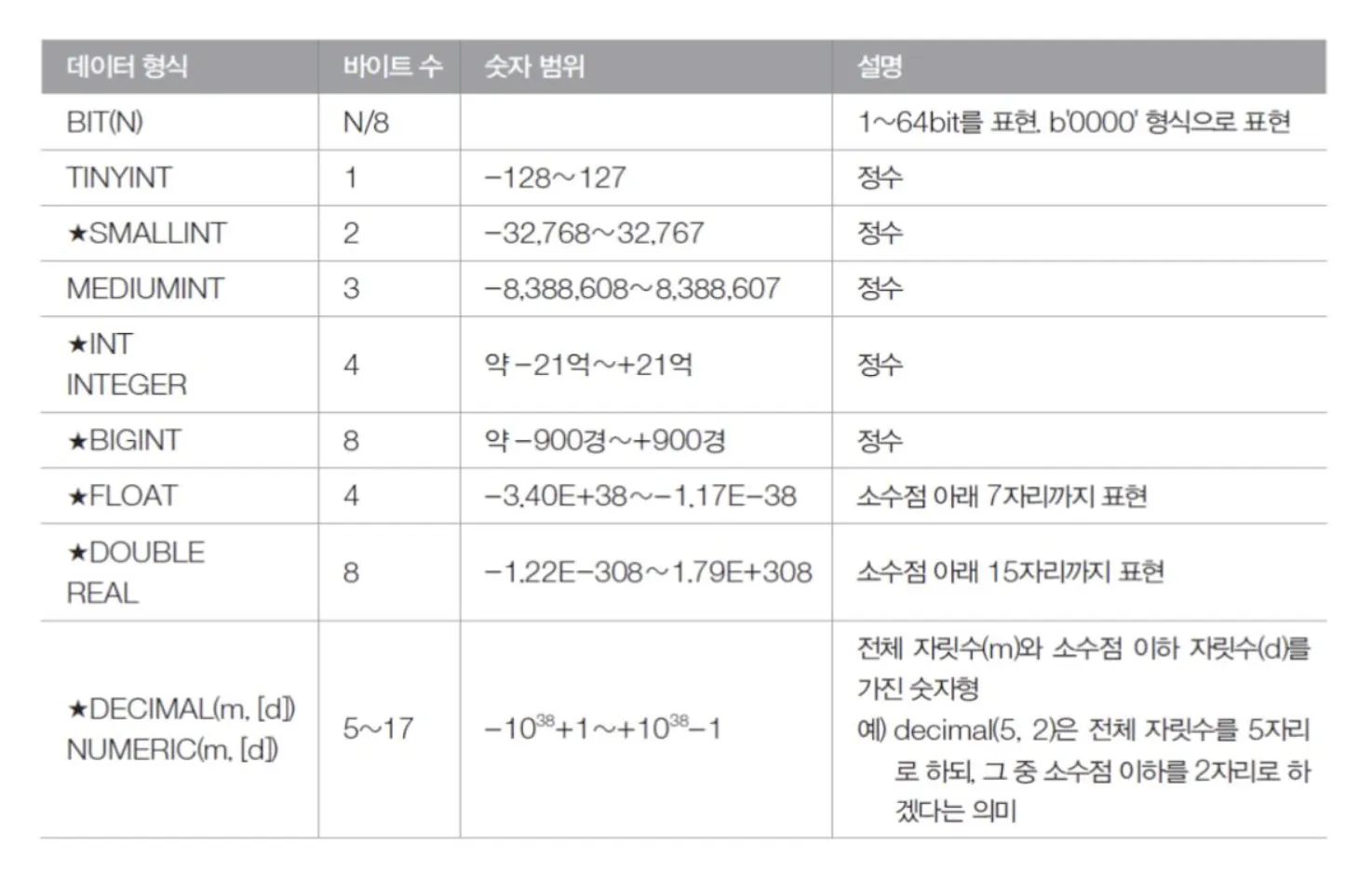
데이터 타입 - 숫자
•
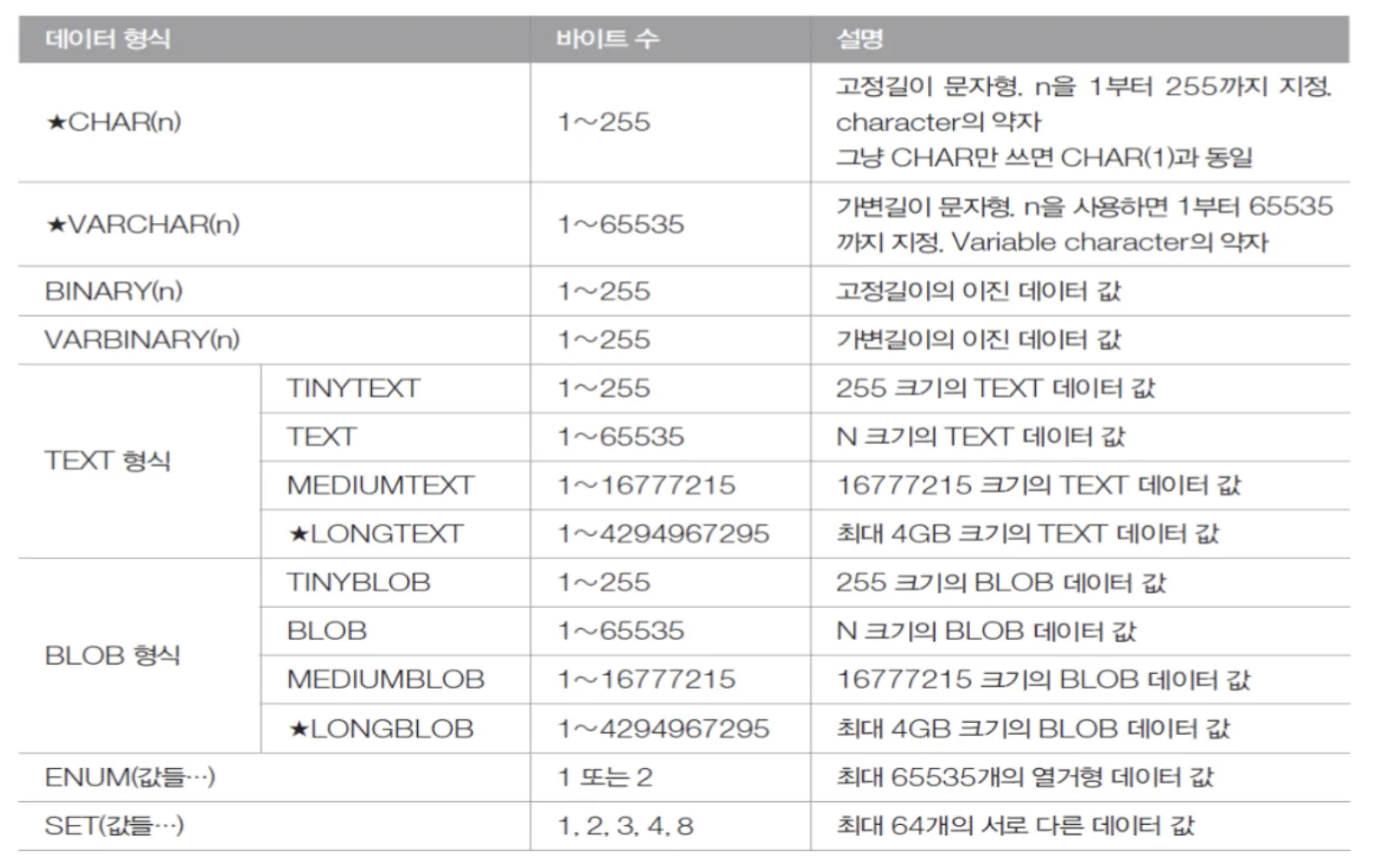
데이터 타입 - 문자
•
데이터 타입 - 날짜

테이블 옵션
•
ENGINE - 데이터를 디스크에 ‘쓰기’ 하거나 저장된 데이터를 ‘읽기’ 하는 역할을 한다.
•
InnoDB
◦
기본값으로 설정되는 스토리지 엔진
Transaction-safe, Commit, Rollback, 데이터 복구 기능, Row-Level Locking 제공
데이터를 Clustered index에 저장하여 PK 기반의 query의 I/O 비용을 줄임
FK 제약을 제공하여 데이터 무결성을 보장
•
MylSAM
◦
트랜잭션을 지원하지 않고 Table-Level Locking을 제공
Multi-thread 환경에서 성능이 저하 될 수 있음
•
Archive
◦
'로그 수집'에 적합한 엔진
데이터가 메모리상에서 압축되고 압축된 상태로 디스크에 저장
•
auto_increment - 시퀀스의 초기 값을 설정
◦
ALTER TABLE [테이블명] auto_increment=[시작하려는 값]; 으로 초기값 재설정 가능
•
DEFAULT CHARSET - 인코딩 방식 설정
◦
UTF8로 설정하지 않으면 한글 사용 불가능
•
테이블 변경
◦
테이블 이름 수정
ALTER TABLE 이전테이블명 RENAME 새로운테이블명;
SQL
복사
◦
테이블 컬럼 추가
ALTER TABLE 테이블명 ADD COLUMN 컬럼명1 데이터타입, 컬럼명2 데이터타입;
SQL
복사
◦
테이블 변경 - 테이블 컬럼 삭제 (제약 조건이 설정된 경우, 제약 조건 먼저 삭제)
ALTER TABLE 테이블명 DROP 컬럼명1, 컬럼명2;
SQL
복사
테이블 관련 명령
# 테이블 생성
CREATE TABLE contact (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
address VARCHAR(255),
tel VARCHAR(20),
email VARCHAR(255),
birthday DATE
) ENGINE=InnoDB auto_increment=1 DEFAULT CHARSET=utf8mb4;
# 테이블의 컬럼 추가
ALTER TABLE contact ADD COLUMN age INT;
# 테이블 확인
desc contact;
# 테이블 컬럼 삭제
ALTER TABLE contact DROP age;
# 테이블 확인
desc contact;
# 테이블의 기존 컬럼 자료형과 이름 변경
ALTER TABLE contact CHANGE tel phone INT;
# 테이블 확인
desc contact;
# 기존 컬럼 자료형과 이름으로 변
ALTER TABLE contact CHANGE phone tel VARCHAR(20);
# 테이블 확인
desc contact;
# 테이블의 기존 컬럼 자료형만 변경
ALTER TABLE contact MODIFY tel VARCHAR(255);
# 테이블 확인
desc contact;
# 테이블 컬럼 순서 조정 - email을 name 뒤로
ALTER TABLE contact MODIFY COLUMN email VARCHAR(255) AFTER name;
DESC contact;
# 테이블 삭제
DROP TABLE contact;
# 데이터베이스 내부 테이블 확인
SHOW TABLES;
SQL
복사

INSERT INTO students VALUES
(null, '정서연', '2000-12-10', '서울', 'ISTJ'),
(null, '권지훈', '2000-01-31', '서울', 'ISTJ'),
(null, '한민혁', '2000-09-29', '인천', 'ESFP');
INSERT INTO students VALUES
(null, '박진국', '2000-08-21', '인천', 'ISTJ'),
(null, '성제현', '2000-12-05', '대구', 'ESFP');
SQL
복사
•
NULL 허용 여부
◦
기본은 NULL을 허용하는 것이며, 컬럼 제약조건에 NOT NULL을 설정하면, NULL 입력 불가
CREATE TABLE tNullable (
name CHAR(10) NOT NULL,
age INT
);
INSERT INTO tNullable (name, age) VALUES ('흥부', 36);
INSERT INTO tNullable (name) VALUES ('놀부');
# Field 'name' doesn't have a default value (기본값이 있어야 함)
INSERT INTO tNullable (age) VALUES (44); -- 에러
SQL
복사
제약 조건
•
필드 값 종류 제한
◦
컬럼 선언문에 CHECK 키워드와 함께 컬럼값으로 가능한 값을 지정
CREATE TABLE tCitydefault(
name CHAR(10) PRIMARY KEY,
area INT NOT NULL DEFAULT 0,
popu INT NULL DEFAULT 0,
metro ENUM('y', 'n') NOT NULL DEFAULT 'n',
region CHAR(6) NULL
);
INSERT INTO tCityDefault (name, area, popu, region) VALUES
('전주', 712, 34, '경상');
INSERT INTO tCityDefault VALUES
('인천', 1063, 295, 'y', '경기');
INSERT INTO tCityDefault VALUES
('강릉', 131, 24, DEFAULT, '강원');
INSERT INTO tCityDefault (name) VALUES
('군산');
select * from tCitydefault tc ;
-- 인천 지하철 디폴트값으로 표시 --
UPDATE tCityDefault SET metro = DEFAULT WHERE name =
'인천';
name|area|popu|metro|region|
----+----+----+-----+------+
강릉 | 131| 24|n |강원 |
군산 | 0| 0|n | |
인천 |1063| 295|y |경기 |
전주 | 712| 34|n |경상 |
SQL
복사
•
실습
CREATE TABLE tStaffDefault (
name char(15) not null primary key,
-- depart char(10) CHECK(depart = '영업부' or depart = '총무부' or depart = '인사과') DEFAULT '영업부',
depart char(10) ENUM('영업부', '총무부', '인사과') NOT NULL DEFAULT '영업부',
gender CHAR(3) ENUM('남', '여') DEFAULT '0',
grade char(10) NOT NULL DEFAULT '수습',
salary int DEFAULT 280 CHECK(salary > 0),
-- achivement double DEFAULT 1.0
score DECIMAL(5, 2) NOT NULL DEFAULT 1.0
);
ALTER TABLE tStaffDefault ADD COLUMN joindate DATE NOT NULL DEFAULT (CURDATE())
INSERT INTO tStaffDefault(name, gender)
VALUES ('mrnobody', '남')
select * from tStaffDefault;
INSERT INTO tStaffDefault (salary) VALUES (-100);
INSERT INTO tStaffDefault (depart) VALUES ('개발부');
SQL
복사
•
제약조건 - 키
◦
슈퍼키(Super Key)
각 행을 유일하게 식별할 수 있는 하나 또는 그 이상의 속성들의 집합.
슈퍼키는 유일성만 만족하면 슈퍼키가 될 수 있다.
◦
후보키(Candidate Key)
각 행을 유일하게 식별할 수 있는 최소한의 속성들의 집합.
◦
기본키(Primary Key)
후보키 중에서 선정한 키로 테이블에서 오직 1개만 지정 가능.
레코드를 상징하는 값으로 자주 참조하는 속성이어야 한다.
•
기본키 설정 방법
◦
기본키는 NOT NULL 속성을 겸하기에 NOT NULL을 붙일 필요 없다.
◦
제약조건이름은 나중에 편집이나 삭제 등을 편리하게 하기 위해서 사용한다.
◦
복합키로 기본키를 설정하는 경우에는 테이블 제약조건 형태로 설정한다.
(* 2개 이상 컬럼의 조합으로 기본키를 설정하는 것을 복합키라고 한다)
CREATE TABLE 테이블명 (
컬럼명1 타입 [CONSTRAINT 제약조건이름] PRIMARY KEY,
...
);
CREATE TABLE 테이블명 (
컬럼명1 타입 [CONSTRAINT 제약조건이름],
...
CONSTRAINT 제약조건이름 PRIMARY KEY(컬럼명1)
SQL
복사
•
UNIQUE
◦
필드의 중복값을 방지하여 모든 필드가 고유한 값을 가지도록 강제
◦
기본키와 차이점
▪
UNIQUE는 NULL을 허용한다.
▪
UNIQUE와 NOT NULL을 설정하면 기본키와 유사해진다.
CREATE TABLE tSale (
saleno INT AUTO_INCREMENT PRIMARY KEY,
customer VARCHAR(10),
product VARCHAR(30)
);
INSERT INTO tSale(customer, product) VALUES
("단군", "지팡이"), ("고주몽", "고등어");
SELECT * FROM tSale;
DELETE FROM tSale WHERE saleno = 1002;
INSERT INTO tSale(customer, product) VALUES
("박혁거세", "계란");
ALTER TABLE tSale AUTO_INCREMENT = 1000;
INSERT INTO tSale (customer, product) VALUES
("고주몽", "고등어");
SELECT * FROM tSale;
INSERT INTO tSale (customer, product) VALUES
("왕건", "너구리");
// 가장 최근의 ID 값을 확인 후 수정해줌
SELECT LAST_INSERT_ID();
UPDATE tSale SET product="짜파게티" WHERE saleno = LAST_INSERT_ID();
SQL
복사
•
참조 무결성 - 2개의 테이블 생성 (외래키 미설정 상태)
◦
기본 키와 참조 키 간의 관계가 항상 유지됨을 보장할 수 없다.
# 참조 무결성 Example (외래키 설정 :D)
CREATE TABLE tEmployee (
name CHAR(10) PRIMARY KEY,
salary INT NOT NULL,
addr VARCHAR(30) NOT NULL
);
INSERT INTO tEmployee VALUES
('아이린', 650, '대구'), ('슬기', 480, '안산'), ('웬디', 625, '서울');
CREATE TABLE tProject (
projectID INT PRIMARY KEY,
employee CHAR(10) NOT NULL,
project VARCHAR(30) NOT NULL,
cost INT,
CONSTRAINT FK_employee FOREIGN KEY(employee) REFERENCES tEmployee(name)
);
INSERT INTO tProject VALUES
(1, '아이린', '홍콩 수출건', 800),
(2, '아이린', 'TV 광고건', 3400),
(3, '아이린', '매출 분석건', 200),
(4, '슬기', '경영 혁신안 작성', 120),
(5, '슬기', '대리점 계획', 85),
(6, '웬디', '노조 협상건', 24);
-- FOREIGN 키 설정 후 실행 안 됨
-- INSERT INTO tProject VALUES (7, '조이', '원자재 매입', 9000);
-- DELETE FROM tEmployee WHERE name = '아이린';
SQL
복사
•
참조 무결성 옵션 - 참조된 행이 삭제되거나 업데이트 될 때 수행할 작업을 지정
◦
ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
◦
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
▪
NO ACTION : 참조된 행이 수정, 삭제될 때 아무런 작업을 하지 않음
▪
CASCADE : 참조된 행이 수정, 삭제될 때 해당 행을 참조하는 모든 행도 함께 수정, 삭제
▪
SET NULL : 참조된 행이 수정, 삭제될 때 해당 외래 키를 포함하는 열의 값을 NULL로 설정
▪
SET DEFAULT : 참조된 행이 수정, 삭제될 때 해당 외래 키를 포함하는 열의 값을 기본값으로 설정
데이터 모델링
•
관계형 데이터베이스를 구성하는 용어
◦
릴레이션(Relation): 정보 저장의 기본 형태가 2차원 구조인 테이블
◦
속성(attribute): 테이블의 각 열(Column, Field)
◦
도메인(Domain): 속성이 가질 수 있는 값들의 집합
◦
튜플(Tuple): 테이블이 한 행을 구성하는 속성들의 집합(Record, Row)
◦
카디널리티(Cardinality): 서로 다른 테이블 사이에 대응되는 수 (고유 값의 수)
◦
키(key) : 각 튜플들을 유일하게 식별할 수 있는 속성 또는 속성의 집합
[예시 : 학번, {학번, 이름}, {학번, 학년}, {학번, 이름, 학과}]
◦
후보키(Candidate Key) : 유일성과 최소성을 만족하는 속성 또는 속성의 집합
[예시 : 학번]
◦
기본키(Primary Key) : 후보키 중에서 선정한 키로, 튜플들을 유일하게 식별할 수 있는 키
◦
기본키는 null이거나 중복될 수 없음
◦
대체키(Alternate Key) : 기본키를 제외한 나머지 후보키
◦
외래키(Foreign Key) : 다른 테이블의 행을 식별할 수 있는 속성
•
외래키 관계 설정 종류
◦
1 : 1 관계 – 양쪽 테이블의 기본키를 서로 다른 테이블의 외래키로 추가
◦
1 : M 관계 – 1 쪽 테이블의 기본키를, M 쪽 테이블의 외래키로 추가
◦
N : M 관계 – 양쪽 테이블의 기본키를 가지는 별도 테이블을 생성해서 외래키로 설정
◦
테이블에서 참조할 수 없는 외래키를 가져서는 안된다.
◦
즉, 참조하고 있는 테이블에 존재하는 값이거나 null이어야 한다.
•
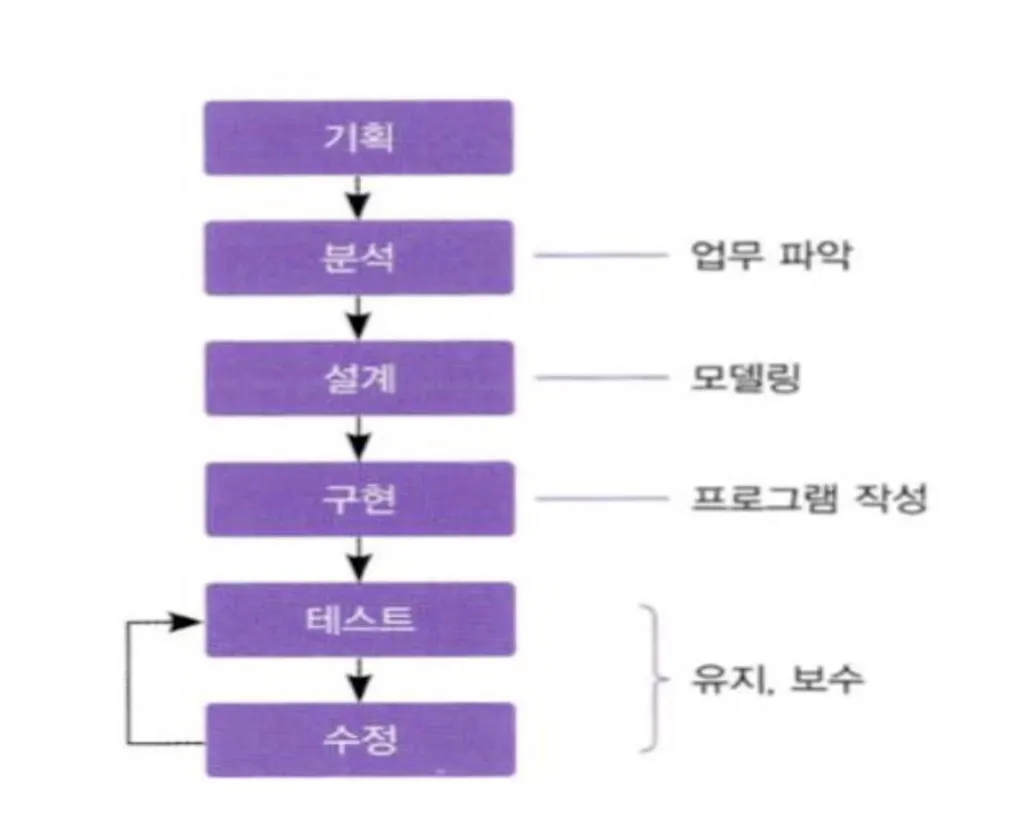
모델링 - 복잡한 현실세계를 일정한 표기법에 의해 표현하는 것!
•
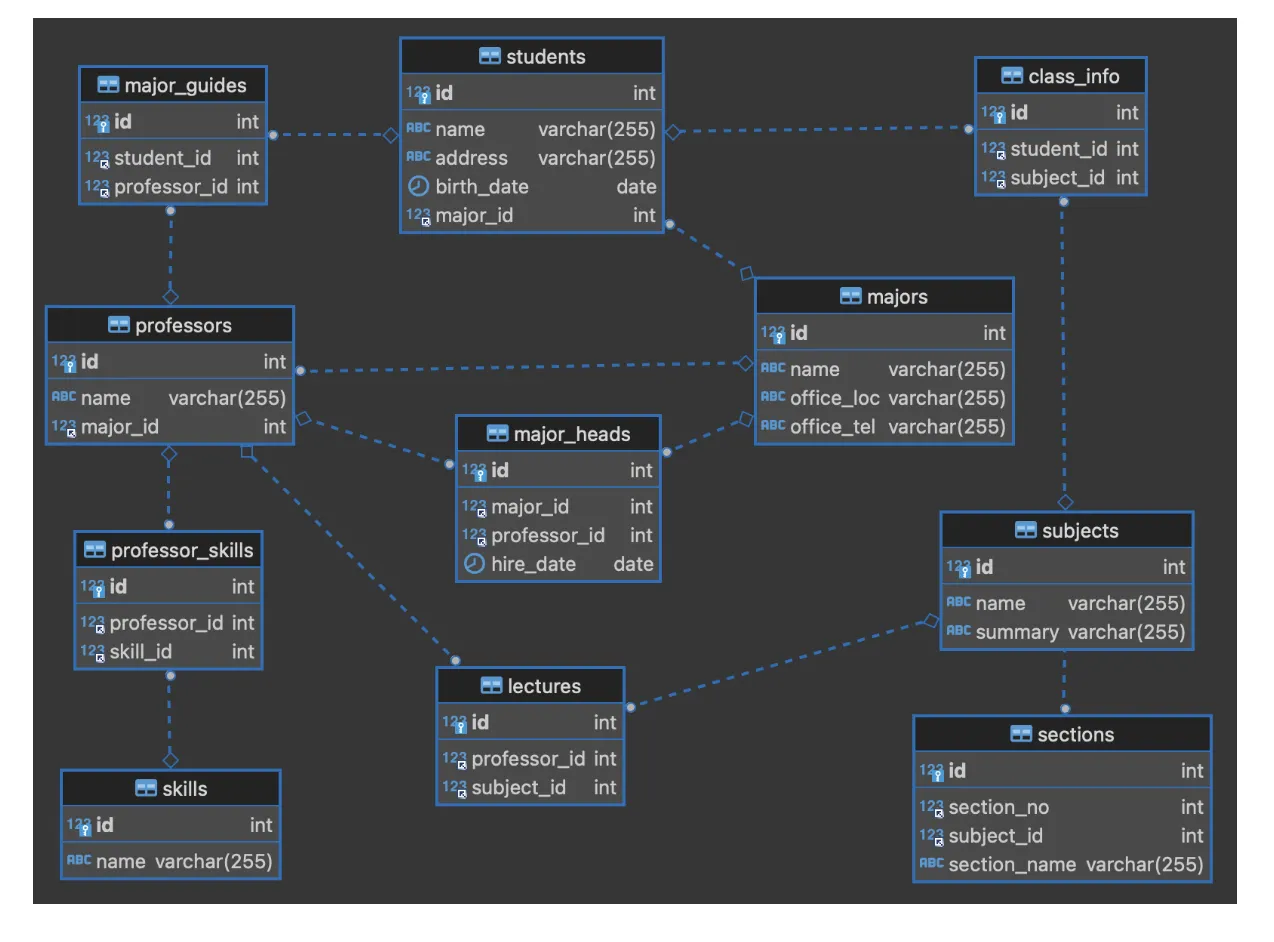
ERD (Entity-Relationship Diagram)
◦
모든 학생은 고유한 학번을 갖고 특정 학과에 소속되며 이름, 주소, 생년월일, 나이를 관리
◦
학과는 학과명, 학과사무실 위치, 전화번호 등을 관리하고 학교 내에서 같은 이름의 학과는 없음
◦
학생은 수강할 과목을 등록하는데 과목에는 과목번호, 과목명, 과목개요 등이 있음
◦
과목은 여러 섹션으로 나누어질 수 있는데 섹션에는 고유한 섹션번호가 있으며 모든 과목이 섹션으로 나
누어지는 것이 아니므로 섹션은 과목이 없으면 존재할 필요가 없고 또한 다른 과목의 섹션은 같은 섹션번
호를 가질 수 있음
◦
교수는 교수번호로 식별할 수 있고 교수이름, 전공분야, 보유기술 등을 관리하며 교수는 여러 개의 보유기
술을 가질 수 있음
◦
교수는 과목을 강의하고 학생에 대해 전공지도를 하는데 일부는 학과의 학과장이 되고 학과마다 학과장
은 한 명씩 있음
데이터베이스 설계
•
설계 과정
◦
요구사항에 대한 분석
▪
조직이나 기관에 대한 일반 사항(회사 내규라든지 조직도 등에 대한 자료 조사)
▪
기존 시스템에 대한 기초 조사(양식지나 컴퓨터 화면 상 입출력 정보 분석)
▪
설문지 작성
▪
담당자 면담
▪
업무 현장 방문
▪
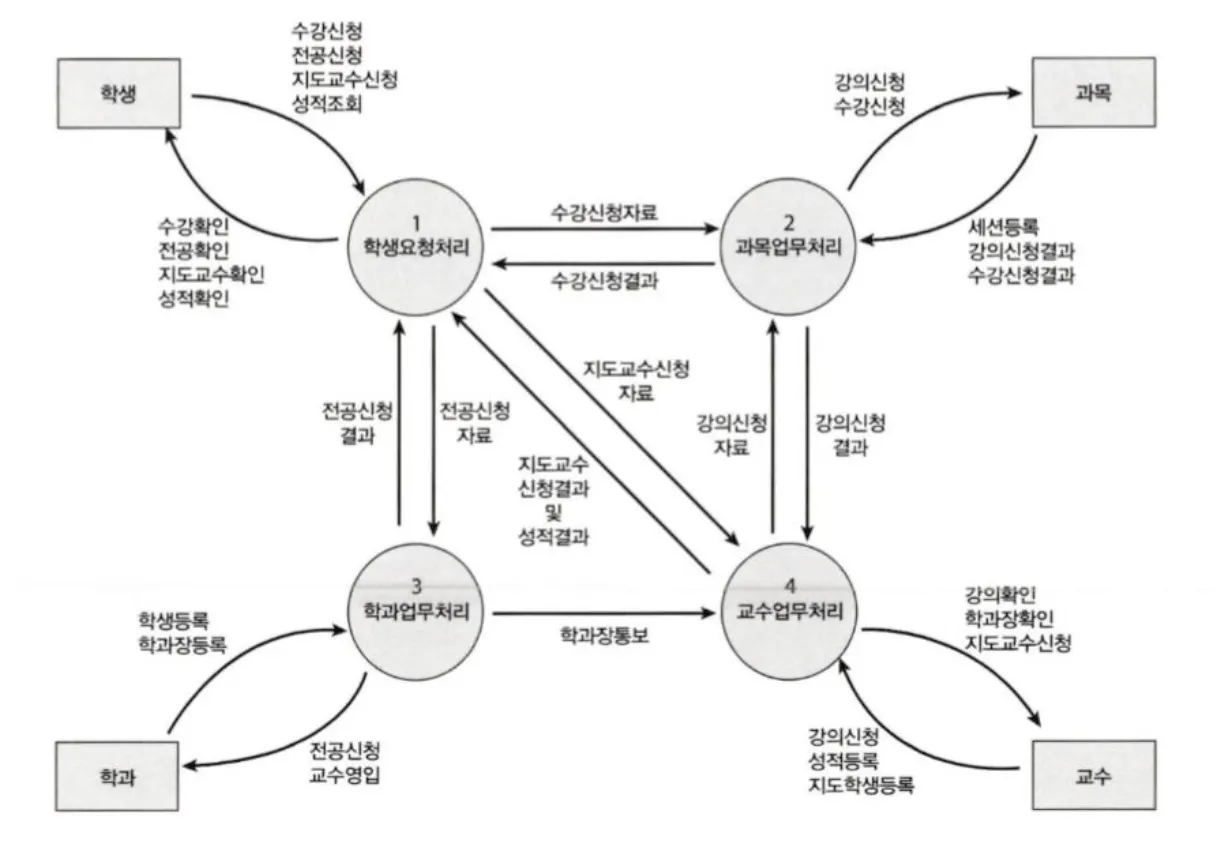
기능에 대한 분석(시스템을 몇 개의 기능 단위로 나누고 다시 기능을 세분화한 단위로 나누며 기능과 기능 사이의 관계를 명확히 정의, 데이터 흐름도(DFD, Data Flow Diagram)를 작성하기도 한다.)
▪
데이터 흐름도 (DFD, Data Flow Diagram)
◦
개념적 설계
▪
개념적 설계는 상향식(Bottom Up)과 하향식(Top Down)으로 나뉜다.
▪
상향식 설계 : DB를 구축하려는 대상에서 데이터 항목을 모두 추출해 낸 후에 비슷한 애트리뷰트를 그룹 지어 엔티티를 만들어서 설계하는 방식
▪
하향식 설계 : DB를 구축하려는 대상을 전체적으로 분석한 후에 엔티티, 애트리뷰트, 관계를 추출하여 설계하는 방식
◦
논리적 설계
▪
DB 관리 시스템을 선정하고 나서는 개념적 설계에서 얻은 산출물을 DB 관리 시스템의 스키마로
변환하는 작업을 하게 되는데 개념 스키마를 논리적 스키마로 변환하는 작업이다.
DB 관리 시스템을 무엇으로 할지 선정하고, 정해진 DB 관리 시스템의 스키마를 만든다.
◦
물리적 설계
▪
인덱스 : DB 내의 레코드에 쉽게 접근하기 위해서 원하는 데이터를 좀 더 빨리 찾게 도와주는 DB의 객체 중 하나로 인덱스의 종류에는 기본 인덱스, 클러스터링 인덱스, 다단계 인덱스, B-tree 인덱스 등이 있음.
▪
역정규화 : 정규화 때문에 분리된 테이블들을 참조할 때 과도한 조인(Join) 연산이 발생하는 것을 방지하기 위해서 정규화에 어긋나는 행위를 하는 것으로 유형에는 칼럼 역정규화, 테이블 분리, 테이블 통합, 요약 테이블 생성 등이 있음.
•
무결성 제약 조건 (Integrity Constraint)
◦
데이터의 내용이 서로 모순되는 일이 없고 데이터베이스에 걸린 제약을 완전히 만족하게 되는 성질
로 데이터베이스의 정합성과 안정성을 준다.
▪
개체 무결성 : 기본키를 구성하는 어떠한 속성값이라도 중복값이나 NULL을 가질 수 없음
▪
참조 무결성 : 참조할 수 없는 외래키 값은 가질 수 없음
(외래키는 NULL을 가질 수 없으며 참조하는 릴레이션의 기본키와 동일해야 함)
▪
도메인 무결성 : 각 속성 값은 반드시 정의된 도메인만을 가져야 함
•
함수적 종속 (Functional Dependency)
◦
완전 함수 종속 (Full Functional Dependency)
기본키를 구성하는 모든 속성이 포함된 기본키의 집합에 종속된 경우,
기본키가 하나의 속성으로 구성된 경우는 모든 속성이 기본키에 대하여 무조건 완전 함수적 종속
◦
부분 함수 종속 (Partial Functional Dependency)
기본키가 여러 속성으로 구성되어 있을 경우 기본키를 구성하는 속성 중 일부에 종속되는 경우
◦
이행적 함수 종속 (Transitive Functional Dependency)
X, Y, Z라는 3 개의 속성이 있을 때 X→Y, Y→Z 이란 종속 관계가 있을 경우, X→Z가 성립되는 경우
X를 알면 Y를 알고, 그를 통해 Z를 알 수 있다.
•
이상 현상 (Anomaly)
◦
정규화를 거치지 않은 DB 내에 데이터들이 불필요하게 중복되어 릴레이션 조작 시
발생하는 예기치 않은 현상
◦
삽입 이상(Insertion Anomaly)
새 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제
◦
변경 이상(Modification Anomaly)
중복된 데이터들 중 일부만 수정하여 데이터가 불일치하게 되는 모순이 발생하는 문제
◦
삭제 이상(Deletion Anomaly)
데이터를 삭제하면 필요한 데이터까지 함께 삭제하여 데이터가 손실되는 연쇄 삭제 문제
정규화
•
논리 데이터 모델을 일관성 있고 안정성 있는 자료 구조로 만드는 단계
•
데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성을 위한 방법으로 데이터를 분해하는 과정
•
정규화의 강점
1.
중복값이 줄어듬
2.
NULL 값이 줄어듬
3.
복잡한 코드로 데이터 모델을 보완할 필요가 없음
4.
새로운 요구 사항의 발견 과정을 도움
5.
업무 규칙의 정밀한 포착을 보증
6.
데이터 구조의 안정성을 최대화
•
실무에서는 보통 1차 정규화부터 중복이 최소로 발생하는 3차 정규화까지 진행
•
제1정규화: 한 릴레이션을 구성하는 모든 도메인이 원자값으로 구성
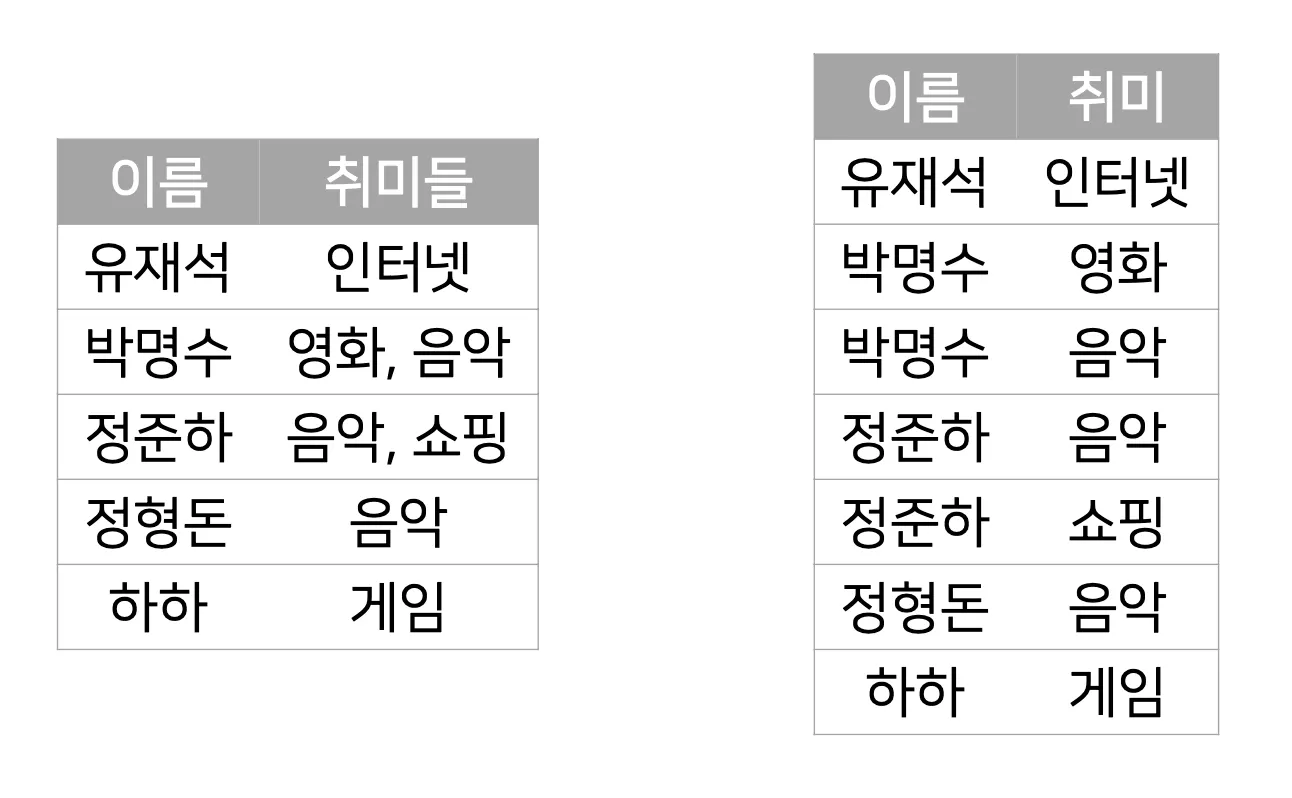
•
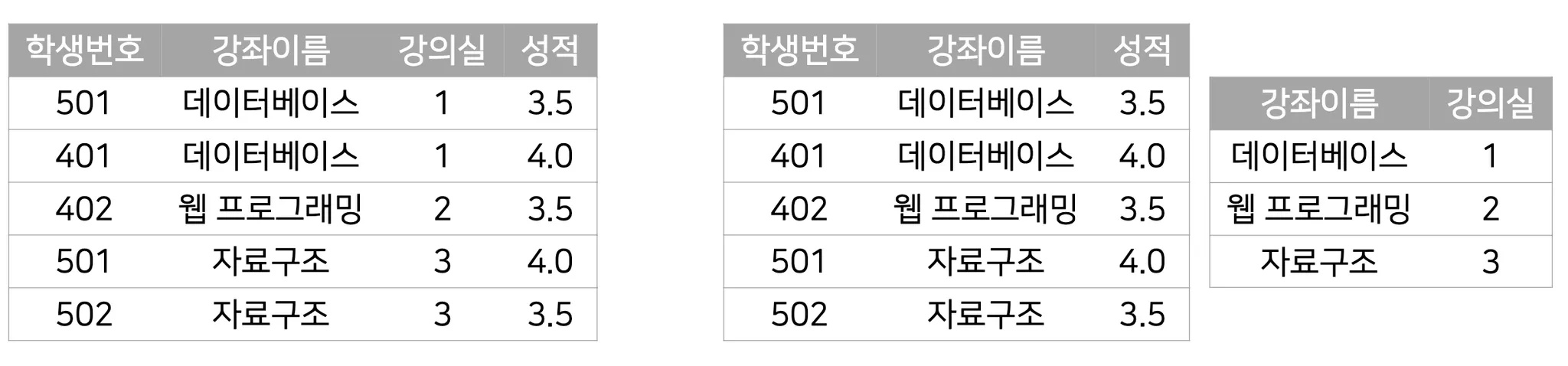
제2정규화: 제1정규화를 만족하면서 모든 속성이 기본키에 완전 함수 종속이 되도록 테이블을 분해
•
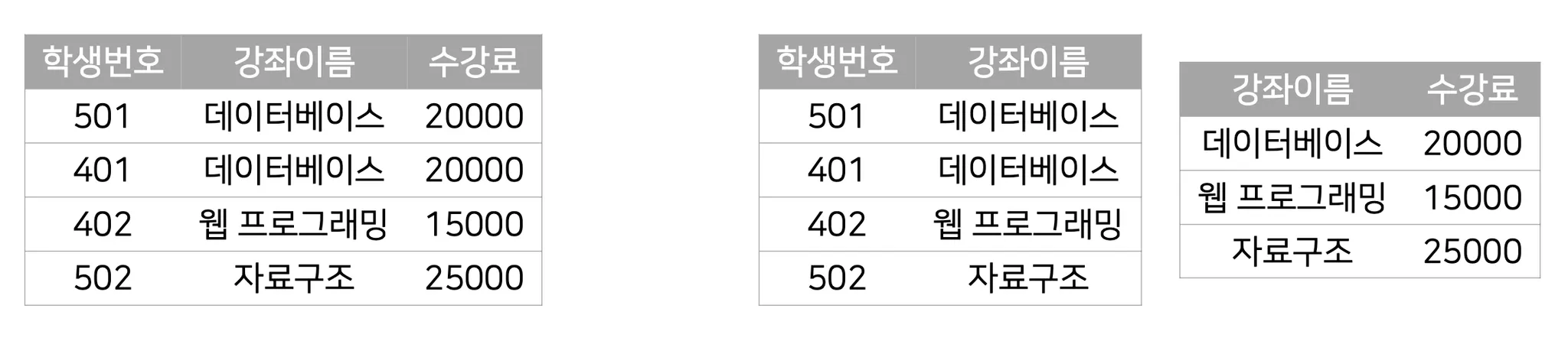
제3정규화 : 제2정규형를 만족하면서 이행적 함수 종속관계를 없애고 비이행적 함수 종속관계를 만족하도록 분해
•
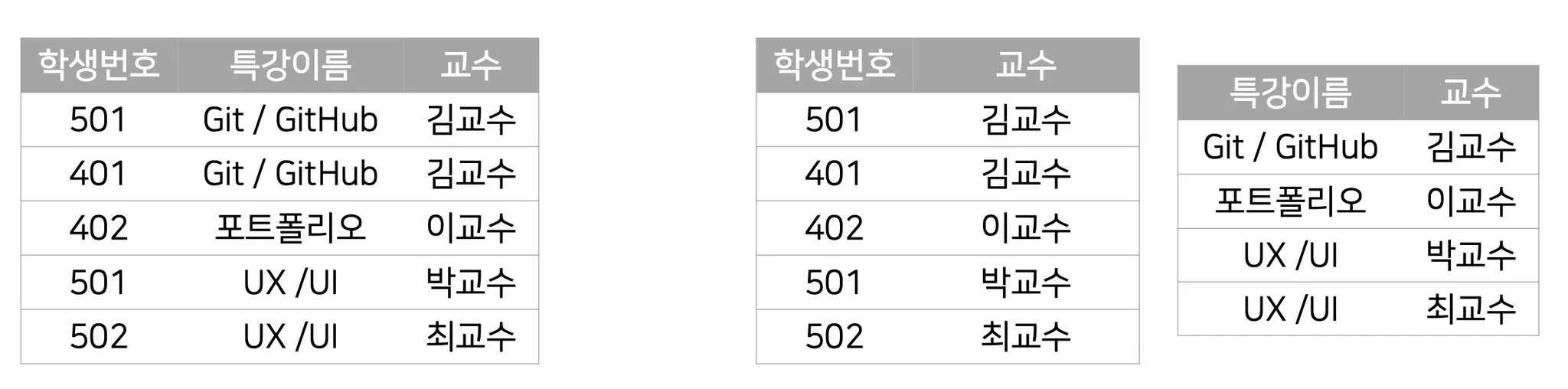
보이스-코드 정규화(BCNF): 제3정규형을 만족하면서 모든 결정자가 후보키가 되도록 테이블을 분해
•
제4정규화: BCNF를 만족하면서 테이블에서 다치 종속 관계를 제거
◦
*다치 종속(Multi-valued Dependency) : 같은 테이블 내의 독립적인 두 개 이상의 컬럼이 또 다른 컬럼에 종속되는 것

•
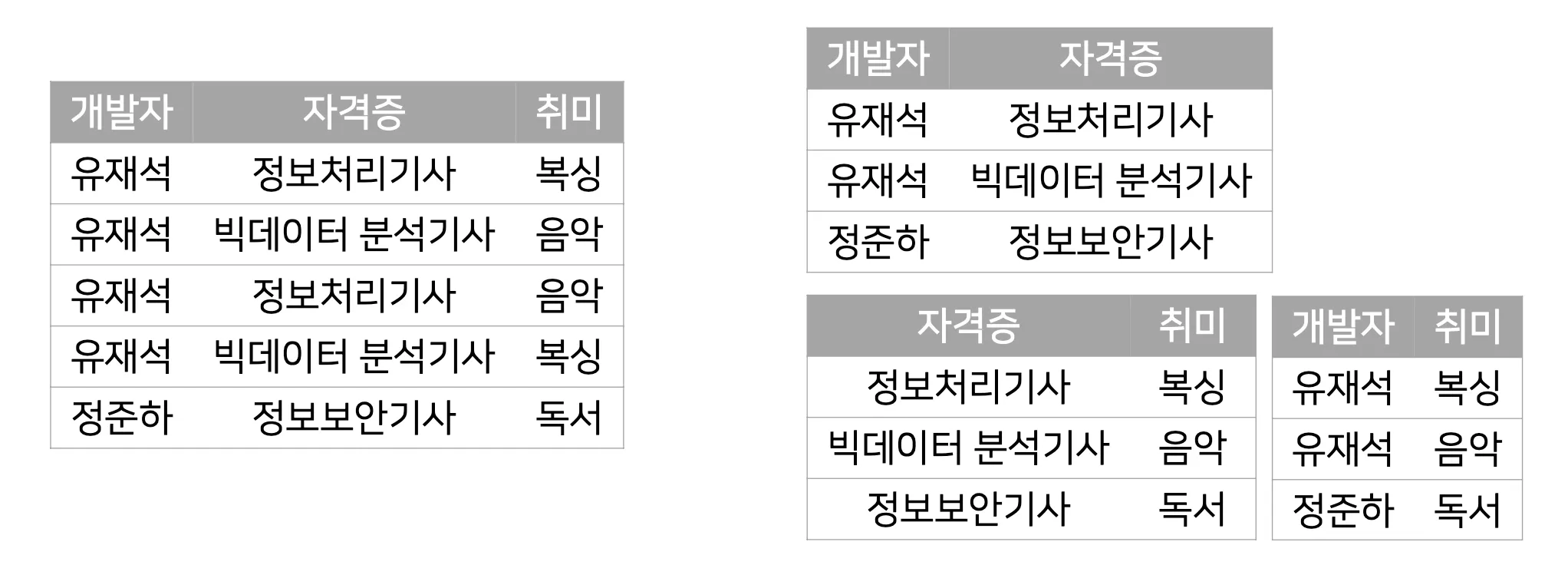
제5정규화: 제4정규화를 만족하면서 후보키를 통하지 않은 조인종속(Join Dependency)을 제거
◦
*조인 종속(Joint Dependency) : 여러 개의 테이블로 분해 후, 다시 조인했을 때 데이터 손실이 없고 필요 없는 데이터가 생기는 것
•
정규화 장단점
◦
장점
▪
업무 변경에 유연한 대처가 가능, 높은 확장성
▪
인덱스 수의 감소
▪
속성 추가의 가능성이 높을 때 사용
◦
단점
▪
빈번한 Join 연산의 증가
▪
부자연스러운 DB
▪
조회/검색 위주의 응용시스템에 부적합하다.
기억장치의 성능이 좋아지고, 저렴해지면서 정규화의 중요성이 저하되고, 성능을 우선 시하게 되는 경향이 있다.
⇒ 기억장치의 성능이 좋아지고, 저렴해지면서 정규화의 중요성이 저하되고, 성능을 우선시하게 되는 경향이 있다.
SNS 데이터베이스 구성하기
•
데이터베이스 생성
drop database if exists kostagram;
create database kostagram default character set = 'utf8mb4';
use kostagram;
SQL
복사
•
users 테이블 생성
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(100) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL,
password VARCHAR(255) NOT NULL,
bio TEXT,
profile_pic VARCHAR(255),
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted_at DATETIME
);
SQL
복사
•
posts 테이블 생성
CREATE TABLE posts (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL UNIQUE,
content TEXT,
image VARCHAR(255),
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted_at DATETIME,
foreign key(user_id) REFERENCES users(id) on delete cascade
);
SQL
복사
•
likes 테이블 생성
CREATE TABLE likes (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
post_id INT NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
deleted_at DATETIME,
foreign key(user_id) REFERENCES users(id) on delete cascade,
foreign key(post_id) REFERENCES posts(id) on delete cascade,
unique key(user_id, post_id)
);
SQL
복사
•
followers 테이블 생성
CREATE TABLE followers (
id INT AUTO_INCREMENT PRIMARY KEY,
following_id INT NOT NULL UNIQUE,
followed_id INT NOT NULL UNIQUE,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
deleted_at DATETIME,
foreign key(followed_id) REFERENCES users(id) on delete cascade,
foreign key(following_id) REFERENCES users(id) on delete cascade,
unique key(followed_id, following_id)
);
SQL
복사
•
데이터 삽입
# 데이터 삽입
INSERT INTO users (name, email, password) values
("류준열", "ryu@gmail.com", "1234"),
("혜리", "hr@gmail.com", "1234"),
("한소희", "hsh@gmail.com", "1234"),
("최인규", "choi@gmail.com", "1234");
insert into posts (`user_id`, `content`, `image`) values
(2, "어이가 없네?", "hr.jpg"),
(3, "환승 아닙니다", "hsh.jpg");
SQL
복사
•
사용자 목록 조회
select * from users where deleted_at is null;
SQL
복사
•
게시물 전체 조회
select * from posts p
join users u on p.user_id = u.id
where p.deleted_at is null;
SQL
복사
•
특정 사용자 게시물 조회
select p.*, u.name from posts p
join users u on p.user_id = u.id
where p.deleted_at is null and u.id = 3;
SQL
복사
•
팔로우 하기
insert into `followers` (following_id, followed_id)
values (1, 1) on duplicate key update deleted_at = null;
SQL
복사
•
언팔로우 하기
update 'followers'
set delete_at = now()
where following_id = 2 and followed_i = 1 and deleted_at is null;
select f.id, ing.name `팔로우한`, ed.name `팔로우 당한` from followers f
join users ing on ing.id = f.following_id
join users ed on ed.id = f.followed_id
where f.deleted_at is null;
SQL
복사
•
특정 사용자가 특정 게시물 좋아요
insert into `likes` (user_id, post_id)
values(1, 2) on duplicate key update deleted_at = null;
SQL
복사
•
특정 사용자가 특정 게시물 좋아요 취소
update `likes`
set deleted_at = now()
where user_id = 1 and post_id = 1 and deleted_at is null;
SQL
복사
•
특정 사용자 팔로워 수, 팔로잉 수 조회
select
(select count(*) from followers where following_id = 1 group by following_id) as "내가 팔로잉",
(select count(*) from followers where followed_id = 1 group by followed_id) as "나를 팔롱";
SQL
복사
•
특정 사용자 팔로워 목록 조회
select ing.* from followers f
join users ing on f.following_id = ing.id
join users ed on f.followed_id = ed.id
where ed.id = 3;
SQL
복사
•
특정 사용자 팔로잉 목록 조회
select ed.* from followers f
join users ing on f.following_id = ing.id
join users ed on f.followed_id = ed.id
where ing.id = 3;
SQL
복사