


복습 - 키워드로 정리
•
API 도큐먼트
•
애노테이션
•
Object 클래스
•
제네릭
멀티 스레드
•
하나의 프로세스가 두 가지 이상의 작업을 처리할 수 있는 이유는 멀티 스레드(Multi Thread)가 있기 때문이다.
•
스레드(Thread)는 코드의 실행 흐름을 말하는데, 프로세스 내에 스레드가 두 개라면 두 개의 코드 실행 흐름이 생긴다는 의미이다.
멀티 프로세스 : 프로그램 단위의 멀티 태스킹
멀티 스레드 : 프로세스 단위의 멀티 태스킹 (프로그램 내부)
=> ex) 카카오톡에서 동영상을 보내는 동안 메세지 전송
Plain Text
복사
•
멀티 프로세스는 서로 독립적이므로 하나의 프로세스에서 오류가 발생해도 다른 프로세스에 영향을 미치지 않지만, 멀티 스레드는 하나의 스레드가 예외를 발생시키면, 프로세스가 종료되므로 다른 스레드에게 영향을 미친다.
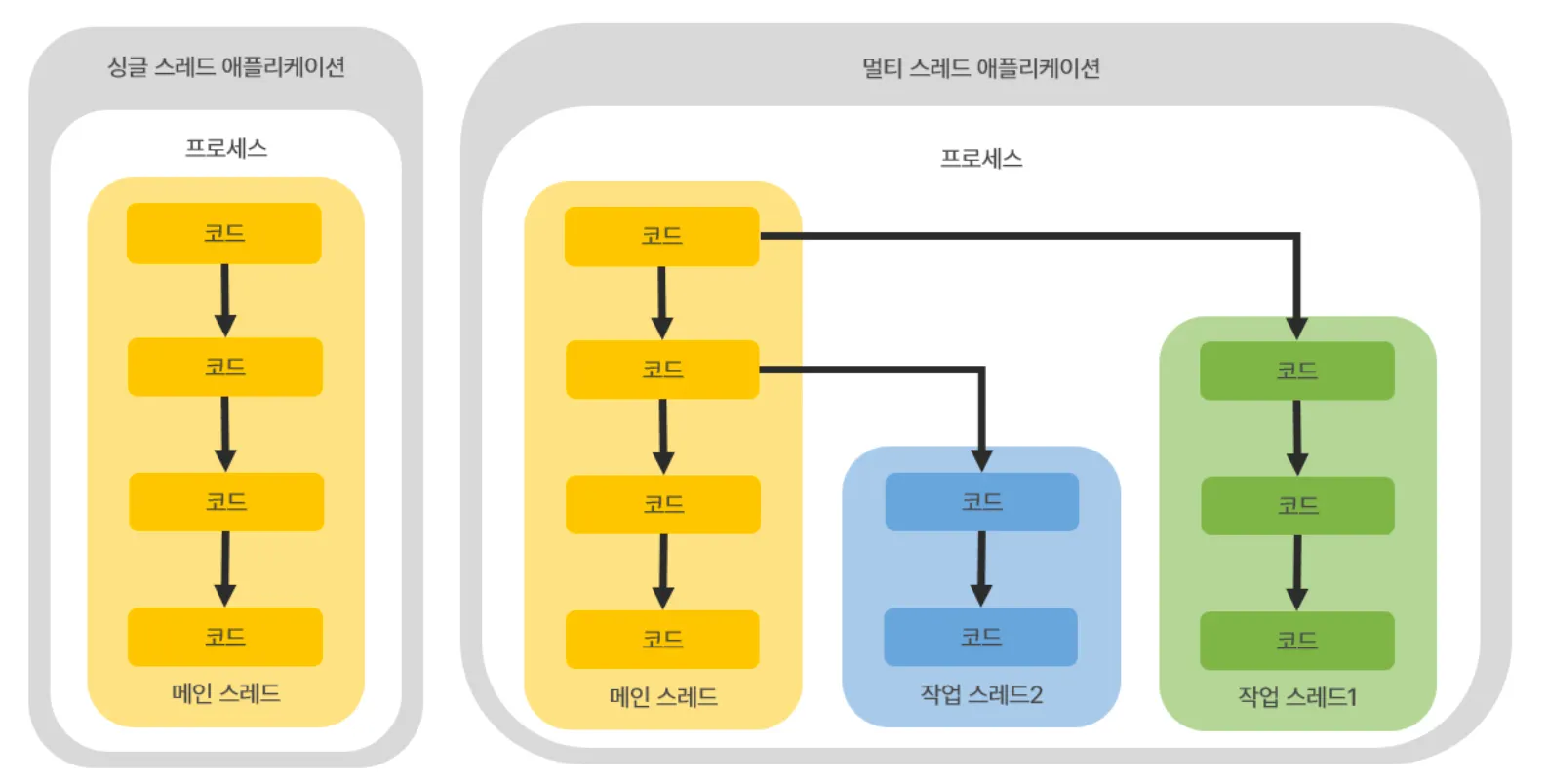
멀티 스레드 - 메인 스레드, 작업 스레드 생성과 실행
•
모든 Java 프로그램은 메인 스레드(Main Thread)가 main() 메소드를 실행하면서 시작된다.
•
메인 스레드는 main() 메소드의 첫 코드부터 순차적으로 실행하고 main( ) 메소드의 마지막 코드를 실행하거나 return 문을 만나면 실행을 종료한다.
•
멀티 스레드 환경에서는 실행 중인 스레드가 하나라도 있다면 프로세스가 종료되지 않는다.
•
메인 스레드는 반드시 존재하기 때문에 추가적인 작업 수만큼 스레드를 생성한다.

•
작업 스레드도 객체로 관리하기 때문에 클래스가 필요하다.
◦
Thread 클래스로 직접 객체를 생성하는 방법
◦
하위 클래스를 만들어 생성하는 방법
멀티 스레드 - Thread 클래스로 직접 스레드 생성하기
•
java.lang 패키지에는 Thread 클래스로부터 작업 스레드 객체를 직접 생성하기 위해서는
Runnable 구현 객체를 매개값으로 갖는 생성자를 호출하면 된다.
•
Runnable은 스레드가 작업을 실행할 때 사용하는 인터페이스로, 그 안에는 run( ) 메소드가 정의되어 있다
•
구현 클래스는 run( ) 메소드에 스레드가 실행할 코드를 재정의(오버라이딩)해주면 된다.
•
일반적으로는 명시적인 Runnable 구현 클래스를 작성하지 않고, 익명 구현 객체를 통해 작성하는 방식이 더 많이 사용된다.
package com.thread;
public class ThreadExample1 {
public static void main(String[] args) {
// Thread thread = new Thread(/* Runnable 인터페이스 */);
// Thread thread = new Thread(new Task());
Thread thread = new Thread(new Runnable() {
@Override // => 익명 객체 형태를 더 많이 사용한다.
public void run() {
// 작업 스레드가 처리할 코드
for (int i = 1000; i > 0; i--) {
System.out.println("스레드 " + i);
}
}
});
// 해당 스레드를 시작시킨다.
thread.start();
thread.start();
thread.start();
thread.start();
thread.start();
for (int i = 0; i < 1000; i++) {
System.out.println("메인 " + i);
}
}
}
Java
복사
package com.thread;
public class ThreadExample1 {
public static void main(String[] args) {
// Thread thread = new Thread(/* Runnable 인터페이스 */);
// Thread thread = new Thread(new Task());
Thread thread = new Thread(new Runnable() {
@Override // => 익명 객체 형태를 더 많이 사용한다.
public void run() {
// 작업 스레드가 처리할 코드
for (int i = 5; i > 0; i--) {
System.out.println("스레드 " + i);
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
// 해당 스레드를 시작시킨다.
thread.start();
// 메인 스레드
for (int i = 0; i < 5; i++) {
System.out.println("메인 " + i);
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
Java
복사
멀티 스레드 - Thread 자식 클래스로 스레드 생성하기
•
작업 스레드 객체를 생성하는 또 다른 방법은 Thread의 자식 객체로 만드는 것이다.
•
Thread 클래스를 상속한 다음 run( ) 메소드를 재정의해서 스레드가 실행할 코드를 작성하고 객체를 생성하면 된다.
package com.thread;
public class ThreadExample2 {
public static void main(String[] args) {
// Thread thread = new Thread의 자식 클래스();
Thread thread = new WorkerThread();
// 해당 스레드를 시작시킨다.
thread.start();
// 메인 스레드
for (int i = 0; i < 5; i++) {
System.out.println("메인 " + i);
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
// ================
메인 0
스레드 5
스레드 4
메인 1
스레드 3
메인 2
스레드 2
메인 3
스레드 1
메인 4
Java
복사
멀티 스레드 - 스레드 상태
•
스레드 상태는 Thread.State 타입으로 정의되어 있다.
(NEW, RUNNABLE, TERMINATED, TIMED_WAITING, BLOCKED, WAITING)
•
RUNNABLE - 실행과 실행 대기 반복, CPU를 다른 스레드들과 나눠 사용
◦
RUNNABLE 상태에서는 상황에 따라 TIMED_WAITING, BLOCKED, WAITING 상태로
전환될 수 있다.
package com.thread2;
public class ThreadStateExample {
public static void main(String[] args) {
// 스레드의 상태
// NEW : 스레드가 생성된 후, start 전
// RUNNABLE : start 후 실행 준비가 된 상태 (실행 중일 수도.. 실행 대기일 수도..)
// TERMINATED : 실행 종료
Thread.State state;
Thread thread = new Thread() {
@Override
public void run() {
for (int i = 0; i < 1000000000; i++) {
}
}
};
state = thread.getState(); // enum 타입이어서 사용 가능
System.out.println("스레드 상태1: " + state); // 스레드 상태1: NEW
thread.start();
state = thread.getState();
System.out.println("스레드 상태2: " + state); // 스레드 상태2: RUNNABLE
try {
// CPU를 해당 10억번 작업 스레드가 모두 사용하도록 메인 스레드 대기
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
state = thread.getState();
System.out.println("스레드 상태3: " + state); // 스레드 상태3: TERMINATED
}
}
Java
복사
멀티 스레드 - 스레드 일시정지
•
예시 - 다운로드 한 폴더를 여는 과정
package com.thread3;
public class ThreadA extends Thread {
@Override
public void run() {
ThreadB threadB = new ThreadB();
threadB.start();
try { // 스레드 일임을 한다.
threadB.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread.currentThread().setName("폴더 열기");
String name = Thread.currentThread().getName();
System.out.println(name + " 시작");
System.out.println("폴더를 엽니다."); // 다운로드 완료되면
System.out.println(name + " 끝");
}
}
Java
복사
package com.thread3;
public class ThreadB extends Thread {
@Override
public void run() {
Thread.currentThread().setName("다운로드");
String name = Thread.currentThread().getName();
System.out.println(name + " 시작");
for (int i = 0; i <= 100; i += 10) {
System.out.println("다운로드: " + i + "%");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(name + " 끝");
}
}
Java
복사
package com.thread3;
public class ThreadPauseExample {
public static void main(String[] args) {
Thread thread = new Thread(new ThreadA());
thread.start();
}
}
Java
복사
멀티 스레드 - 스레드 양보
•
스레드가 처리하는 작업은 반복처리가 많은 편인데, 가끔은 반복이 무의미한 반복으로 처리되는 경우가 있다.
•
이 때는 다른 스레드에게 실행을 잠시 양보하고, 자신은 실행 대기 상태로 가는 것이 프로그램 성능에 도움을 준다.
•
Thread는 yield( ) 메소드를 제공하여, yield( )를 호출한 스레드는 실행 대시 상태로 돌아가고, 다른 스레드가 실행 상태가 된다.
package com.thread4;
public class ThreadLoop extends Thread {
public boolean work = true;
@Override
public void run() {
while (true) {
if (work) {
System.out.println(Thread.currentThread().getName() + "의 작업처리");
} else {
Thread.yield();
}
}
}
}
Java
복사
package com.thread4;
public class ThreadLoopExample {
public static void main(String[] args) {
ThreadLoop thread0 = new ThreadLoop();
ThreadLoop thread1 = new ThreadLoop();
thread0.setName("첫번째 스레드");
thread1.setName("두번째 스레드");
thread0.start();
thread1.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
thread0.work = false;
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
thread0.work = true;
}
}
Java
복사
멀티 스레드 추가 내용
•
스레드 동기화
◦
멀티 스레드는 하나의 객체를 공유해서 작업도 할 수 있다. 하지만 다른 스레드에서 객체를 조작한다면, 의도했던 결과와는 다른 결과를 초래할 수 있다. 스레드가 사용 중인 객체를 다른 스레드가 변경할 수 없도록 객체에 잠금을 걸 수 있다.
◦
동기화 메소드와 동기화 블록은 동시 접근이 불가능하다.
•
wait(), notify()
◦
두 개의 스레드를 가지고 정확히 교대로 번갈아가며 작업하도록 처리할 수 있다.
◦
한 스레드가 작업을 완료하면 notify( ) 메소드를 호출해, 일시정지에 있는 다른 스레드를 실행대기 상태로 만들고, 자신은 두 번 작업을 하지 않도록 wait( ) 메소드를 호출하여 일시정지 상태로 만든다.
◦
주의할 점은 wait(), notify() 메소드 모두 동기화 메소드 또는 동기화 블록 내에서만 사용 가능하다는 것이다.
•
스레드 안전 종료
◦
조건 분기 처리 또는 interrupt( ) 메소드 사용으로 후, 리소스 정리 작업을 추가하는 것으로 스레드를 안전하게 종료할 수 있다.
•
데몬 스레드
◦
데몬 스레드는 주 스레드의 작업을 돕는 보조적인 스레드로, 주 스레드가 종료되면 자동으로 종료된다.
◦
데몬 스레드로 만들기 위해서는 start( ) 호출 전에 setDaemon(true)를 호출하면 된다
자료구조
•
선형 자료구조
◦
데이터가 순차적으로 배열되는 자료구조
◦
배열, ArrayList, LinkedList, Stack, Queue 등등…
◦
List는 연속방식과 연결방식으로 나뉜다.
▪
연속 방식 (메모리 공간 기반) ⇒ 한 번 정해진 길이를 변경할 수 없다!
▪
연결 방식 (포인터_메모리주소번지 기반) - LinkedList
◦
동적 배열의 원리 - 더블링 (시간복잡도 1에 수렴)
▪
미리 초기값을 잡아 배열의 길이를 정해서 생성하고 데이터가 추가되면 늘려주고, 모두 복사해서 만들어준다.
▪
더블링은 진행될 때마다 O(n)이다. 하지만 자주 일어나는 것이 아니므로 O(1)로 간주하고 프로그래밍을 하는 것이 일반적이다.
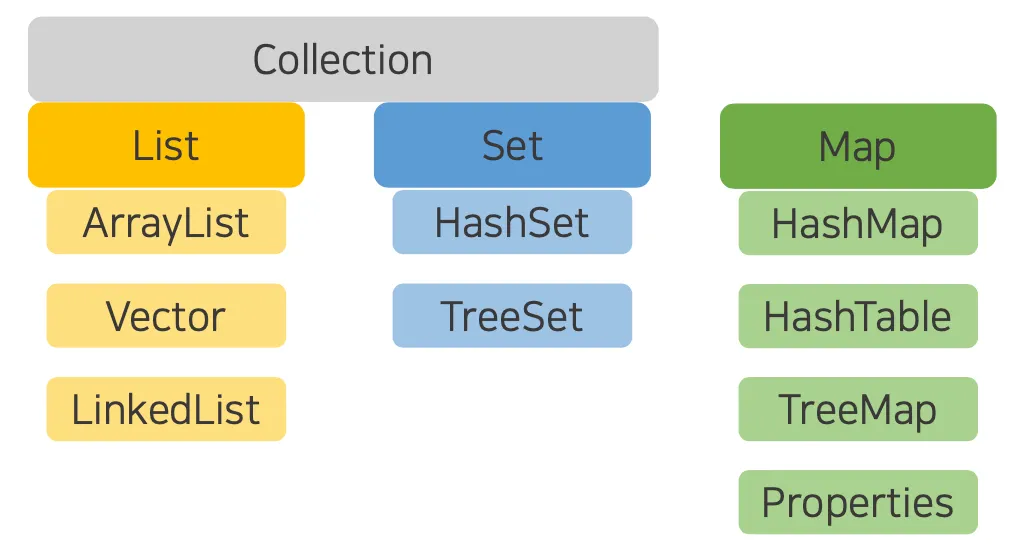
컬렉션 자료구조
•
자료구조를 바탕으로 객체들을 효율적으로 이용할 수 있도록 관련된 인터페이스와 클래스들을 java.util 패키지에 포함시켜 놓았다.
•
이들을 총칭해서 컬렉션 프레임워크(Collection Framework)라고 부른다.
•
컬렉션 프레임워크는 몇 가지 인터페이스를 통해서 다양한 컬렉션 클래스를 이용할 수 있도록 설계되어 있다.
•
주요 인터페이스로는 List, Set, Map 등이 있다.
컬렉션 자료구조

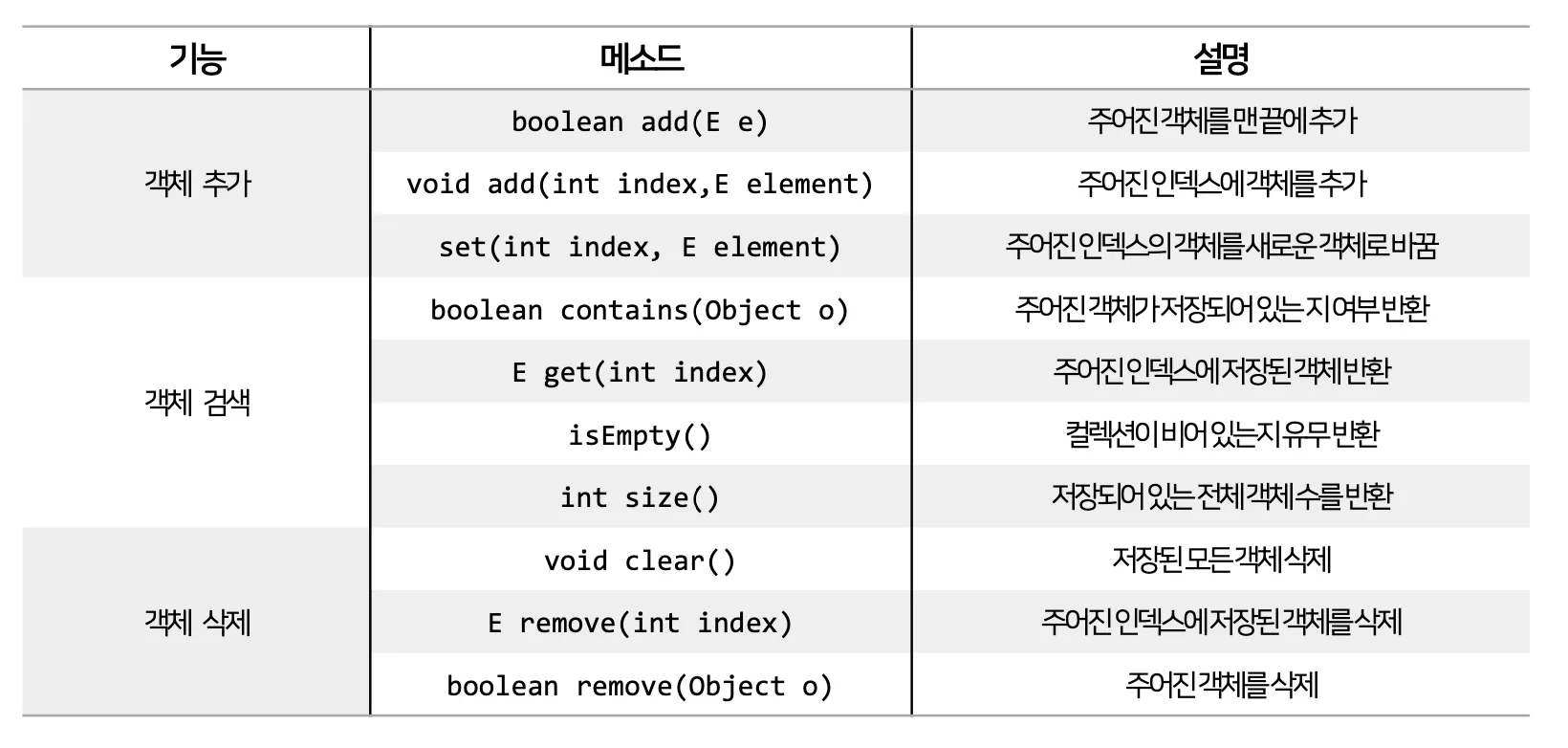
컬렉션 자료구조 - List 컬렉션
•
객체를 인덱스로 관리하기에 객체를 저장하면 인덱스가 부여되고, 인덱스로 객체를 검색, 삭제할 수 있는 기능을 제공한다.
•
ArrayList
◦
List 컬렉션에서 가장 많이 사용되는 컬렉션이다.
◦
ArrayList는 제한 없이 객체를 추가할 수 있다.
List<E> list = new ArrayList<>() ; // E에 지정된 타입의 객체만 저장
List<E> list = new ArrayList<E>(); // E에 지정된 타입의 객체만 저장
List list = new ArrayList(); // 모든 타입의 객체를 저장
Java
복사
Vector
•
Vector는 ArrayList와 동일한 내부 구조를 가지고 있으며, 동기화된 메소드로 구성되어 있어서 멀티 스레드가 동시에 Vector 메소드를 실행할 수 없다는 점에서 차이가 있다.
•
멀티 스레드 환경에서도 안전하게 객체를 추가, 삭제할 수 있다.
List<E> list = new Vector<E>(); // E에 지정된 타입의 객체만 저장
List<E> list = new Vector<E>(); // E에 지정된 타입의 객체만 저장
List list = new Vector(); // 모든 타입의 객체를 저장
Java
복사
컬렉션 자료구조 - List 컬렉션(LinkedList)
•
LinkedList는 ArrayList와 사용 방법은 동일하지만 내부 구조는 완전히 다르다.
•
ArrayList는 내부 배열에 객체를 저장하지만, LinkedList는 인접 객체를 사슬 형태로 연결해서 관리한다.
List<E> list = new LinkedList<E>(); // E에 지정된 타입의 객체만 저장
List<E> list = new LinkedList<E>(); // E에 지정된 타입의 객체만 저장
List list = new LinkedList(); // 모든 타입의 객체를 저장
Java
복사
•
비교
package com.collection.list;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class LinkedListExample {
public static void main(String[] args) {
// ArrayList 객체 생성 [문자열]
List<String> list1 = new ArrayList<>();
// LinkedList 객체 생성 [문자열]
List<String> list2 = new LinkedList<>();
// 시간 측정을 위한 변수 선언
long startTime;
long endTime;
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
list1.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.println("추가 시 걸린 시간 (ArrayList): " + (endTime - startTime));
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
list2.add(0, String.valueOf(i));
}
endTime = System.nanoTime();
System.out.println("추가 시 걸린 시간 (LinkedList): " + (endTime - startTime));
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
list1.get(i);
}
endTime = System.nanoTime();
System.out.println("조회 시 걸린 시간 (ArrayList) : " + (endTime - startTime));
startTime = System.nanoTime();
for (int i = 0; i < 10000; i++) {
list2.get(i);
}
endTime = System.nanoTime();
System.out.println("조회 시 걸린 시간 (LinkedList) : " + (endTime - startTime));
}
}
// ==========================================
추가 시 걸린 시간 (ArrayList): 5314333
추가 시 걸린 시간 (LinkedList): 961125
조회 시 걸린 시간 (ArrayList) : 296125
조회 시 걸린 시간 (LinkedList) : 47712083
Java
복사
컬렉션 자료구조 - Set 컬렉션
•
List 컬렉션은 저장 순서를 유지하지만, Set 컬렉션은 저장 순서가 유지되지 않는다.
또한 객체를 중복해서 저장할 수 없고, 하나의 null만 저장할 수 있다.
•
Set 컬렉션은 수학의 집합에 비유될 수 있다.
•
Set 컬렉션은 순서가 없기 때문에 인덱스로 관리하지 않는다. 즉, 인덱스를 매개값으로 갖는 메소드가 없다.
•
Set 컬렉션에는 HashSet, LinkedHashSet, TreeSet 등이 있는데,
Set 컬렉션에서 공통적으로 사용 가능한 Set 인터페이스 메소드는 아래와 같다.

HashSet
•
Set 컬렉션 중에서 가장 많이 사용되는 것이 HashSet이다.
•
HashSet은 hashCode( ) 메소드의 리턴값이 같고, equals( ) 메소드가 true를 반환하면 동일한 객체로 판단하고 중복 저장하지 않는다.
package com.collection.list;
public class Member {
private String name;
private int age;
public Member(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return name.hashCode() + age;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Member) {
Member m = (Member) obj;
return m.name.equals(name) && m.age == age;
}
return false;
}
}
// ==========================================
package com.collection.list;
import java.util.HashSet;
public class SetExample2 {
public static void main(String[] args) {
// HashSet 컬렉션 객체 생성
HashSet<Member> hashSet = new HashSet<>();
// 동일한 데이터 입력
hashSet.add(new Member("minsung", 26));
hashSet.add(new Member("minsung", 26));
// 저장된 객체 수를 출력
System.out.println("저장된 객체 수 : " + hashSet.size());
}
}
// 저장된 객체 수 : 1
Java
복사
package com.collection.list;
import java.util.HashSet;
import java.util.Set;
public class SetExample {
public static void main(String[] args) {
// HashSet 컬렉션 객체 생성
Set<String> set = new HashSet<>();
// 컬렉션 객체에 데이터 저장 - 순서 X
set.add("Java");
set.add("JDBC");
set.add("JSP");
set.add("JPA");
set.add("Servlet");
set.add("MyBatis");
set.add("Java");
System.out.println("저장된 요소의 개수 : " + set.size());
System.out.println(set);
}
}
Java
복사
TreeSet
•
이진 트리(Binary Tree)를 기반으로 검색 기능을 강화한 Set 컬렉션이다.
•
이진 트리는 여러 개의 노드(node)가 트리 형태로 연결된 구조로, 루트 노드라고 불리는 하나의 노드에서 시작해 각 노드에 최대 2개의 노드를 연결할 수 있는 구조를 가지고 있다.
•
TreeSet에 저장되는 객체는 저장과 동시에 오름차순으로 정렬된다.
(낮은 것은 왼쪽 자식 노드에, 높은 것은 오른쪽 자식 노드에 저장)
•
어떤 객체든지 오름차순으로 정렬될 수 있는 것은 아니고, Comparable 인터페이스를 구현하고 있는 객체만이 정렬 가능하다.
•
Set 타입 변수에 대입해도 되지만, TreeSet 타입으로 대입한 이유는 검색 관련 메소드가 TreeSet에만 정의되어 있기 때문이다.
TreeSet<E> treeSet = new TreeSet<E>();
TreeSet<E> treeSet = new TreeSet<>();
Java
복사
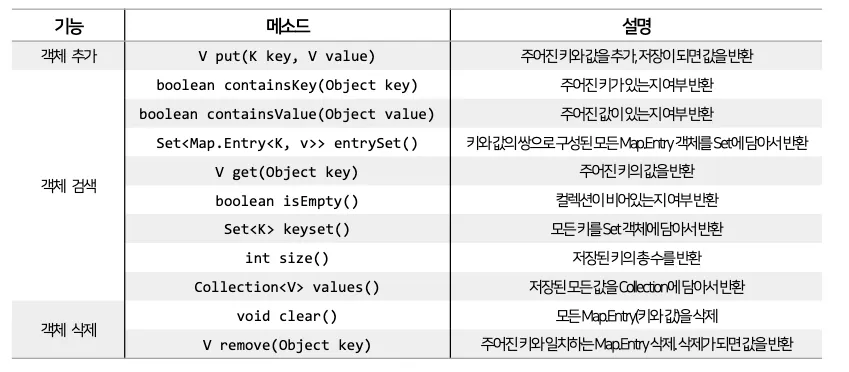
Map
•
Map 컬렉션은 키(Key)와 값(Value)으로 구성된 엔트리(Entry) 객체를 저장한다.
•
키와 값은 모두 객체이고, 키는 중복 저장할 수 없지만 값은 중복 저장할 수 있다는 특징이 있다.
•
만약 동일한 키로 값을 저장하면, 기존의 값이 새로운 값으로 대치된다.
컬렉션 자료구조 - Map 컬렉션(HashMap)
•
HashMap 은 키로 사용할 객체가 hashCode() 메소드의 리턴값이 같고, equals( ) 메소드가 true를 반환하는 경우, 동일 키로 간주하고 중복 저장을 허용하지 않는다.
package com.collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapExample1 {
public static void main(String[] args) {
// 이름과 나이를 가지고, HashMap 컬렉션 생성
Map<String, Integer> map = new HashMap<>();
map.put("김연아", 33);
map.put("지민", 8);
map.put("전지현", 42);
map.put("박보검", 30);
map.put("손흥민", 32);
map.put("지민", 28); // 덮어쓴다.
// 요소의 총 개수
System.out.println("총 entry 수 : " + map.size());
System.out.println(map);
// 키를 통해 값 얻기
Integer sonAge = map.get("손흥민");
System.out.println("손흥민의 나이 : " + sonAge);
// 키로 구성된 set를 구해서, 반복문을 통해 값만 구하기
Set<String> keySet = map.keySet();
Iterator<String> iterator = keySet.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
System.out.println(key);
}
}
}
Java
복사