


DB 학습 내용 복습
•
데이터, 정보, 지식
◦
데이터: 관찰의 결과로 나타난 정량적 혹은 정성적인 실제 값
▪
8848m의 에베레스트 산
◦
정보: 데이터에 의미를 부여한 것
▪
세계에서 가장 높은 산
◦
지식: 사물이나 현상에 대한 이해를 정리한 것
▪
에베레스트 관련 논문, 보고서
•
데이터베이스:
◦
데이터의 집합
◦
데이터의 저장 공간
◦
논리적으로 연관된 데이터를 모아 일정한 형태로 저장해 놓은 것
◦
여러 명의 사용자나 응용프로그램이 공유하는 데이터
◦
응용 시스템들이 공통적으로 사용하기 위해 통합한 것, 저장된 데이터 집합
•
DBMS(Database Management System)
◦
데이터베이스를 관리 및 운영하는 소프트웨어
◦
관계형 DBMS 형태로 사용
▪
MySQL, Oracle, SQL Server, MariaDB 등
◦
DBMS를 이용하여 데이터 입력, 수정, 삭제 등의 기능 제공
•
데이터베이스와 SQL
◦
DBMS가 설치되어 데이터 가진 쪽을 서버(Server), 데이터를 요청하는 쪽을 클라이언트(Client)
라고 한다.
◦
데이터의 일관성 유지, 복구, 동시 접근 제어 등의 기능을 수행
◦
역할
▪
일반 사용자
▪
응용 프로그래머
▪
SQL 사용자
▪
데이터베이스 관리자(DBA)
◦
데이터베이스 시스템은 데이터의 검색(select)과 변경(insert, delete, update 등) 작업을 수행
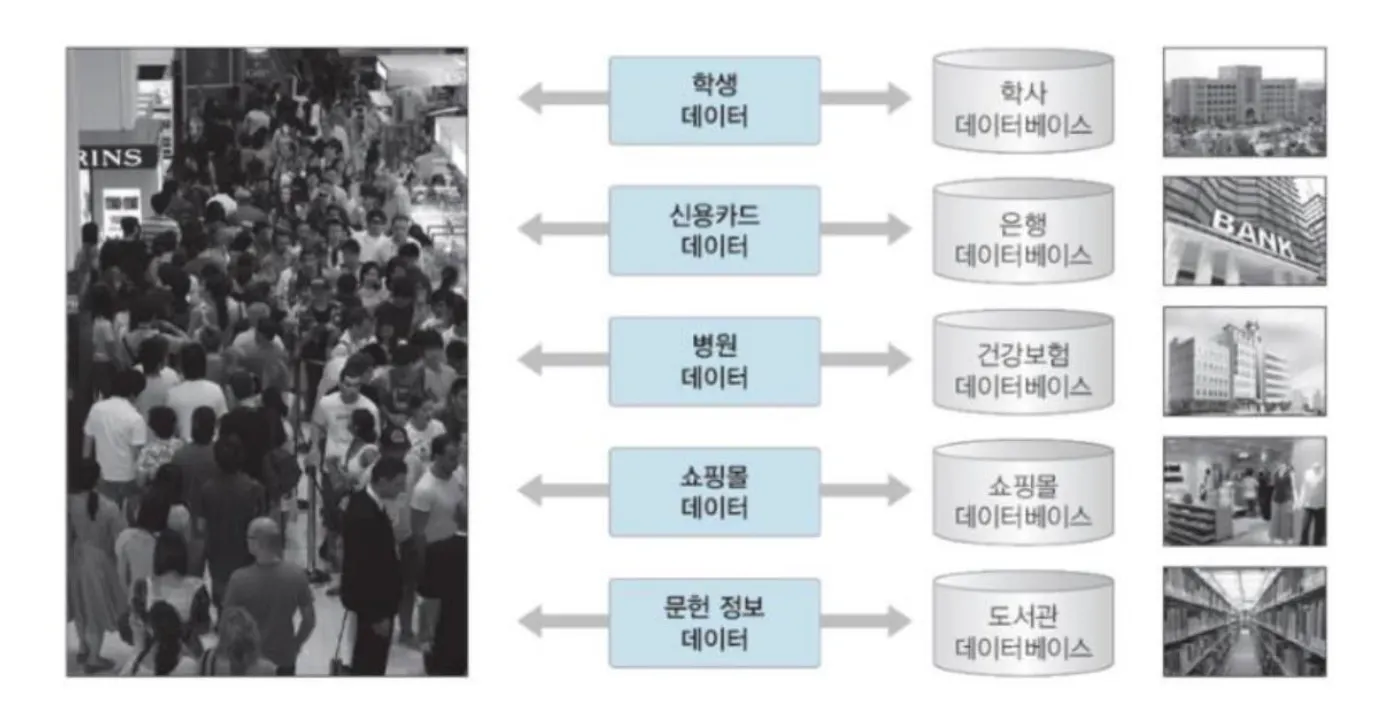
◦
데이터베이스 특징
▪
실시간 접근성
•
DB는 실시간으로 서비스된다.
•
사용자가 데이터 요청하면 몇 초 내에 결과를 보여준다.
▪
계속적인 변화
•
DB에 저장된 내용은 한 순간의 상태이지만, 데이터 값은 시간에 따라 항상 바뀐다.
▪
동시 공유
•
DB는 서로 다른 업무, 여러 사용자에게 동시에 공유된다.
▪
내용에 따른 참조
•
DB에 저장된 데이터는 물리적인 위치가 아니라 값에 따라 참조된다.
데이터베이스 개념
•
통합된 데이터
◦
데이터를 통합하는 개념
◦
각자 사용하던 데이터의 중복을 최소화하여 중복으로 인한 데이터 불일치 제거
•
저장된 데이터
◦
문서로 보관된 데이터가 아니라 컴퓨터 저장장치에 저장된 데이터
•
운영 데이터
◦
조직의 목적을 위해 사용되는 데이터
•
공용 데이터
◦
한 사람 또는 한 업무를 위해 사용되는 데이터가 아니라 공동으로 사용되는 데이터
데이터베이스 종류
•
계층형 DBMS
•
네트워크형 DBMS
•
관계형 DBMS
•
객체지향 DDBMS
•
키-값 (NoSQL) - Not Only SQL
•
시계열 DBMS (TSDB)
관계형 DBMS(R-DBMS)
데이터베이스를 테이블(릴레이션, 엔티티)이라는 최소 단위로 구성되어 있다.
(*테이블은 하나 이상의 열[column]으로 이루어져 있다)
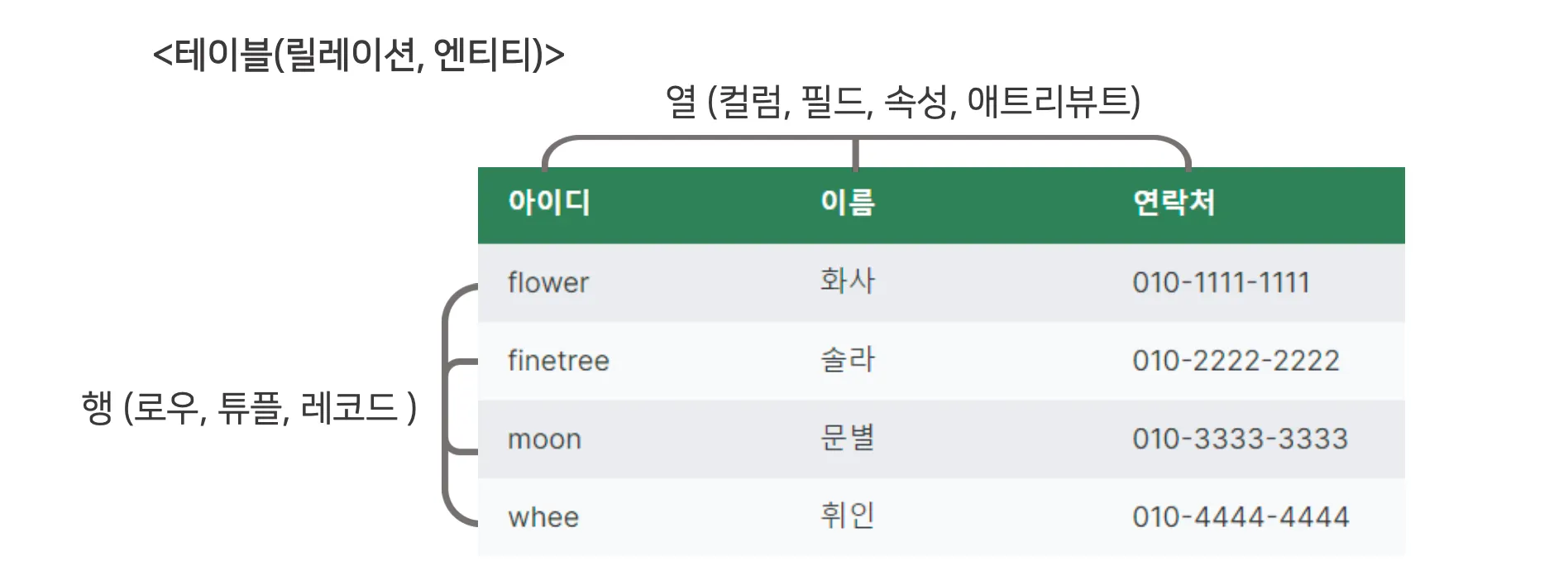
SQL(Structured Query Language)
•
DBMS 제작 회사와 독립적
•
다른 시스템으로 이식성이 좋음
•
표준이 계속 발전 중
•
대화식 언어
•
분산형 클라이언트/서버 구조
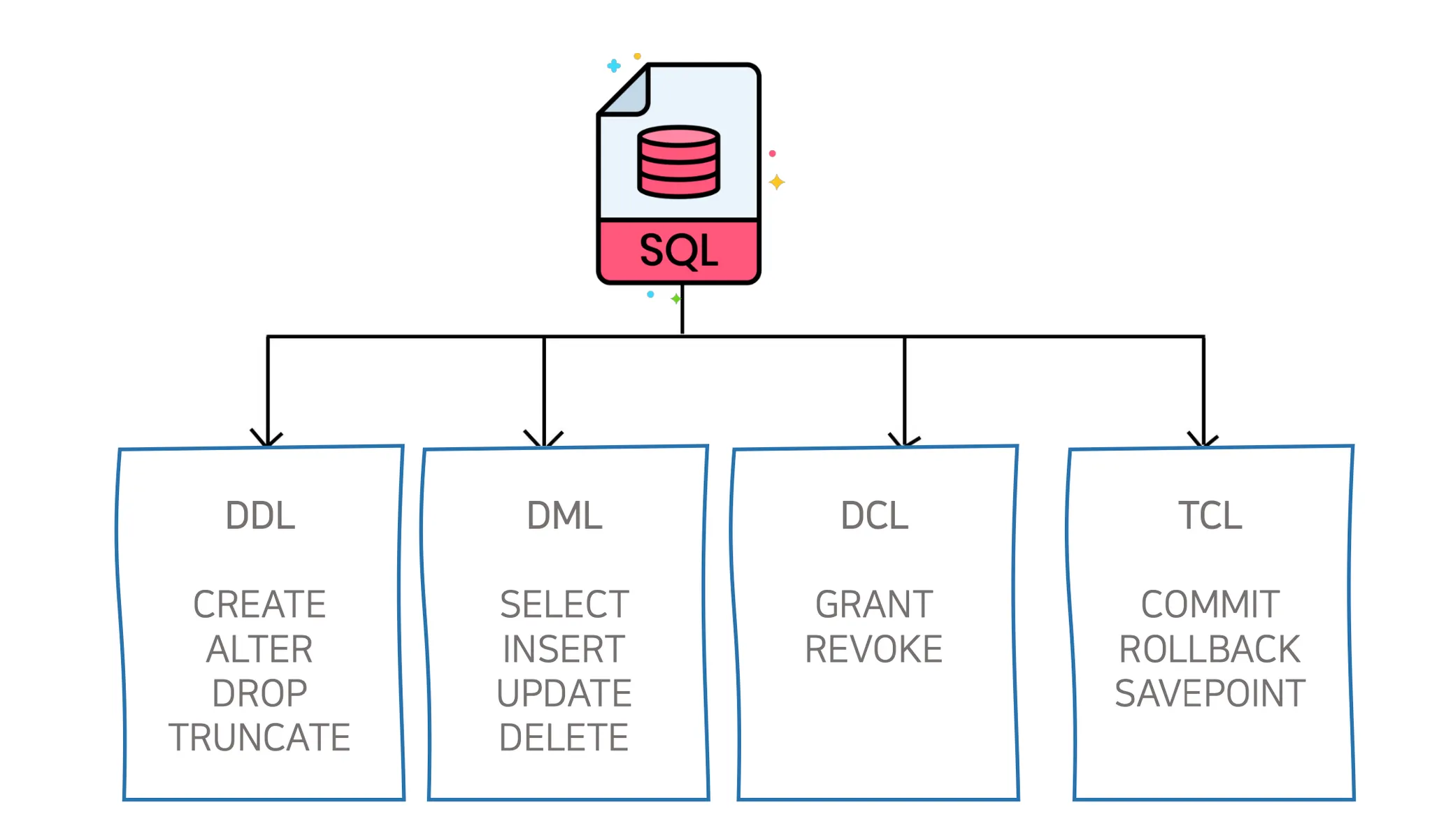
데이터베이스 그리고 SQL
•
DDL
◦
데이터를 정의하는 명령어
◦
create, alter, drop, truncate
•
DML
◦
데이터를 조작하는 명령어
◦
select, insert, update, delete
•
DCL
◦
데이터를 제어하는 명령어
◦
트랜잭션을 제어하거나 데이터 접근권한을 제어할 때 사용
◦
grant, revoke, commit, rollback

MySQL
•
SQL에 기반을 둔 관계형 DBMS
•
3개의 상용 에디션(Standard, Enterprise, Cluster CGE)과 1개의 무료 에디션(Community)
•
리눅스, 유닉스, 윈도우 등 거의 모든 운영체제에서 사용 가능
•
처리가 빠르고 대용량 데이터 처리에 용이
DB 설치 후 실습
•
show databases;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| shop |
| sys |
+--------------------+
SQL
복사
•
exit
mysql> exit
Bye
SQL
복사
•
sample.sql 파일 실행
~/Desktop/test/source $ ls
sample.sql
~/Desktop/test/source $ mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 14
Server version: 8.3.0 Homebrew
Copyright (c) 2000, 2024, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> source sample.sql
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 1 row affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Database changed
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.02 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 8 rows affected (0.00 sec)
Records: 8 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.01 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 20 rows affected (0.00 sec)
Records: 20 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected, 5 warnings (0.01 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 14 rows affected (0.01 sec)
Records: 14 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.01 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 10 rows affected (0.01 sec)
Records: 10 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 13 rows affected (0.00 sec)
Records: 13 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.01 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.01 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| shop |
| study_db |
| sys |
+--------------------+
=> study_db 데이터베이스 추가 완료
SQL
복사
SQL의 특징
•
예약어의 대소문자를 구분하지 않는다.
•
SQL에서 ‘=’는 “같다”의 의미로 사용된다.
•
명령문의 끝맺음은 ‘;(세미콜론);’을 반드시 사용한다.
테이블 조회 - SELECT
•
‘조회’, ‘질의’ 또는 ‘쿼리’라 부르기도 한다.
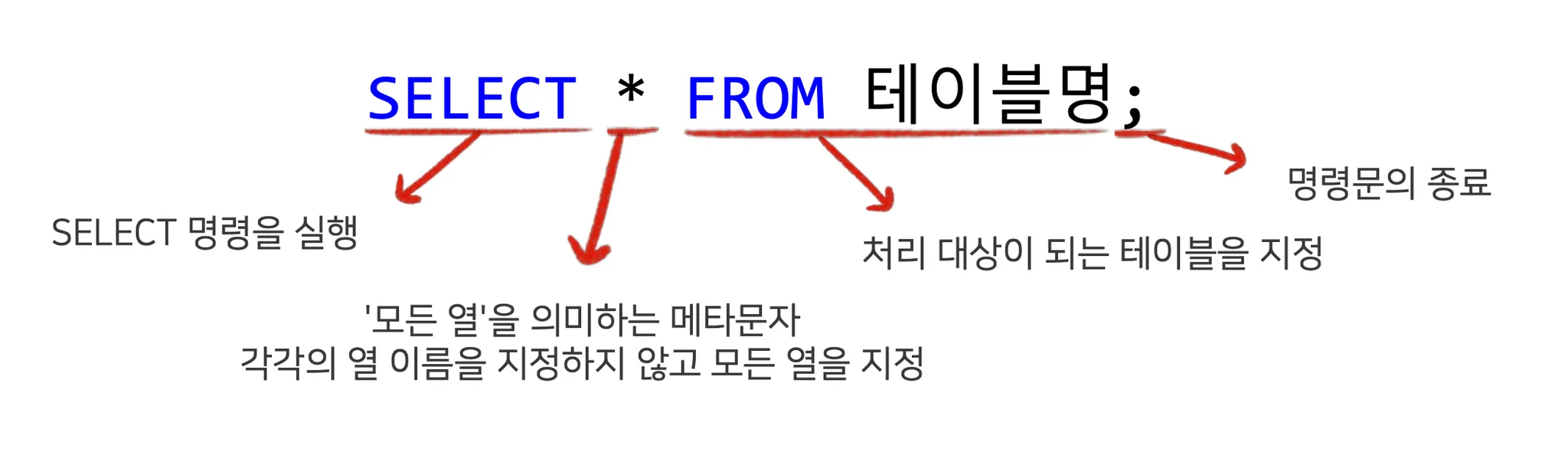
•
“show tables;” 입력하기 ⇒ 조회 테이블 확인
buytbl
DEPT
EMP
logic_operation
promotion_tbl
SALGRADE
tcar
tCity
tmaker
tStaff
usertbl
SQL
복사
•
select * from emp;
mysql> use study_db;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from emp;
-------+--------+-----------+------+------------+---------+---------+--------+
| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |
+-------+--------+-----------+------+------------+---------+---------+--------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-07-13 | 3000.00 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-07-13 | 1100.00 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |
+-------+--------+-----------+------+------------+---------+---------+--------+
14 rows in set (0.00 sec)
SQL
복사
•
SELECT 문법 및 진행 순서
(FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY)

•
select JOB from emp;
CLERK
SALESMAN
SALESMAN
MANAGER
SALESMAN
MANAGER
MANAGER
ANALYST
PRESIDENT
SALESMAN
CLERK
CLERK
ANALYST
CLERK
SQL
복사
•
select distinct job from emp;
CLERK
SALESMAN
MANAGER
ANALYST
PRESIDENT
SQL
복사
•
테이블 데이터, 테이블 열 이름으로 조회하는 쿼리
# 테이블 데이터 조회
select * from emp;
# 테이블 열 이름으로 조회
select JOB from emp;
# 테이블 중복 제거하여 조회
select distinct JOB from emp;
SQL
복사
•
select count(distinct job) from emp;
select count(DISTINCT job) from emp;
count(DISTINCT job)|
-------------------+
5|
SQL
복사
•
windows 사용자
◦
bash에서 mysql -u root -p 사용 가능하도록 설정
echo “alias mysql=\”winpty myql\”” > .bash_profile
cat .bash_profile # 내용 확인
SQL
복사
•
select * from tCity;
◦
열 (컬럼/필드/속성/애트리뷰트)
◦
행 (튜플/레코드)
SELECT * FROM tCity tc ;
name|area|popu|metro|region|
----+----+----+-----+------+
부산 | 765| 342|y |경상 |
서울 | 605| 974|y |서울 |
순천 | 910| 27|n |전라 |
오산 | 42| 21|n |경기 |
전주 | 205| 65|n |전라 |
청주 | 940| 83|n |충청 |
춘천 |1116| 27|n |강원 |
홍천 |1819| 7|n |강원 |
SQL
복사
select 명령을 실행하면, 표(테이블) 형태의 데이터가 출력되며 각각의 열은 오직 하나의 자료형만 가지게 된다.
자료형은 숫자, 문자, 날짜 등이 있으며 데이터를 식별하는 분류체계이다.
•
테이블의 구조와 속성 파악 (Describe)
1.
CHAR() : 고정 길이 문자열 정보 속성값으로 받는다.
최소 길이 1byte, 최대 길이 Oracle 2,000 byte, SQL server 8,000 byte
각 공간이 할당되면 변수의 길이가 공간보다 작을 경우 그 차이 길이만큼 공간으로 채워진다!
2.
VARCHAR(): 가변 길이 문자열 정보 속성값으로 가진다.
최소 길이 1byte, 최대 길이 Oracle 4,000 byte, SQL server 8,000 byte
공간이 할당되지만 변수의 길이만큼 가변적으로 메모리에 공간을 할당하기 때문에 속성값의 바이트만 적용된다!!
desc tCity;
Field |Type |Null|Key|Default|Extra|
------+--------+----+---+-------+-----+
name |char(10)|NO |PRI| | |
area |int |YES | | | |
popu |int |YES | | | |
metro |char(1) |NO | | | |
region|char(6) |NO | | | |
desc emp;
Field |Type |Null|Key|Default|Extra|
--------+-----------+----+---+-------+-----+
EMPNO |int |NO |PRI| | |
ENAME |varchar(10)|YES | | | |
JOB |varchar(9) |YES | | | |
MGR |int |YES | | | |
HIREDATE|date |YES | | | |
SAL |float(7,2) |YES | | | |
COMM |float(7,2) |YES | | | |
DEPTNO |int |YES |MUL| | |
############################################################################
• Field : 열 이름
• Type : 자료형
• Null : NULL 허용 여부
• Key : PK 또는 Unique 여부
• Default : 기본값
• Extra : 기타 정보
SQL
복사
테이블 구조와 자료형
INTEGER, INT(BIGINT, MEDIUMINT, SMALLINT, TINYINT) DECIMAL, FLOAT, DOUBLE, REAL, CHAR, VARCHAR, NCHAR,
NVARCHAR, TEXT(LONGTEXT, MEDIUMTEXT, TINYTEXT), DATE, TIME, DATETIME, TIMESTAMP, YEAR,
BLOB(LONGBLOB, MEDIUMBLOB, TINYBLOB), BINARY, VARBINARY, GEOMETRY, GEOMETRYCOLLECTION, LINESTRING,
MULTILINESTRING, POINT , MULTIPOINT, POLYGON , MULTIPOLYGON, JSON, BIT, BOOLEAN, ENUM, SET…
SQL
복사
•
INTEGER 형 : 수치 자료형 중 하나로 정수값을 저장할 수 있는 자료형
•
CHAR : 고정된 길이의 문자열을 저장할 수 있는 자료형 ⇒ 주민번호, 생년월일
•
VARCHAR : 데이터의 크기에 맞춰 저장공간의 크기가 변경되는 가변 길이 문자열 자료형
•
DATE : 2022년 11월 7일과 같이 연월일의 데이터를 저장할 수 있는 날짜 자료형
•
TIME : 7시 10분 25초와 같이 시분초의 데이터를 저장할 수 있는 시간 자료형
테이블 검색
•
열 지정 검색
SELECT 열이름1, 열이름2, 열이름3, … FROM 테이블명;
SQL
복사
•
select name, area, popu from tcity;
name|area|popu|
----+----+----+
부산 | 765| 342|
서울 | 605| 974|
순천 | 910| 27|
오산 | 42| 21|
전주 | 205| 65|
청주 | 940| 83|
춘천 |1116| 27|
홍천 |1819| 7|
SQL
복사
•
select region, name, area from tcity;
region|name|area|
------+----+----+
경상 |부산 | 765|
서울 |서울 | 605|
전라 |순천 | 910|
경기 |오산 | 42|
전라 |전주 | 205|
충청 |청주 | 940|
강원 |춘천 |1116|
강원 |홍천 |1819|
SQL
복사
•
별명 (alias)
◦
간혹 테이블의 컬럼명이 사용자가 읽기에는 직관적이지 못한 경우가 있다. 이런 경우에는 별명을 지정해서, 컬럼명 대신 별명을 출력할 수 있다. 별명은 고유해야 하며, AS는 생략 가능하다. 만약 별명에 공백, 특수문자, 대문자가 있거나 한글로 지정하는 경우에는 백틱(`)을 사용해 지정하는 것을 권장한다.
◦
select region AS `도시명`, popu AS `인구 (만명)`, area AS `면적` from tcit
◦
select region `도시명`, popu `인구`, area `면적` from tcity;
◦
select region `도시명`, popu `인구 (만명)`, area `면적` from tcity;
도시명|인구 (만명)|면적|
---+-------+----+
경상 | 342| 765|
서울 | 974| 605|
전라 | 27| 910|
경기 | 21| 42|
전라 | 65| 205|
충청 | 83| 940|
강원 | 27|1116|
강원 | 7|1819|
SQL
복사
•
where
SELECT name as `도시명`, popu AS `인구` from tcity where metro='n';
도시명|인구|
---+--+
순천 |27|
오산 |21|
전주 |65|
청주 |83|
춘천 |27|
홍천 | 7|
SQL
복사
•
계산
# 산술 표현식
SELECT name `도시명`, popu * 10000 `인구` from tCity tc ;
도시명|인구
---+-------+
부산 |3420000|
서울 |9740000|
순천 | 270000|
오산 | 210000|
전주 | 650000|
청주 | 830000|
춘천 | 270000|
홍천 | 70000|
SQL
복사
SELECT * FROM tCity tc WHERE popu = 300 + 42;
name|area|popu|metro|region|
----+----+----+-----+------+
부산 | 765| 342|y |경상 |
select 1+2+3+4+5
1+2+3+4+5|
---------+
15|
select 1+2+3+4+5 AS `5까지의 합계`;
5까지의 합계|
-------+
15|
## tCity 테이블에서 데이터(name, area, popu, 인구밀도) 조회
# 인구밀도는 인구수를 면적으로 나눈 값
select name, area, popu, popu/area AS `인구밀도` from tCity;
name|area|popu|인구밀도 |
----+----+----+------+
부산 | 765| 342|0.4471|
서울 | 605| 974|1.6099|
순천 | 910| 27|0.0297|
오산 | 42| 21|0.5000|
전주 | 205| 65|0.3171|
청주 | 940| 83|0.0883|
춘천 |1116| 27|0.0242|
홍천 |1819| 7|0.0038|
### SELECT 문을 통해서 1년은 몇 초 인가 계산하기
select 365 * 24 * 60 * 60 AS `1년은 몇 초`;
1년은 몇 초 |
--------+
31536000|
SQL
복사
•
컬럼 연결 (concat)
select concat("최인규", "는", "천재") AS `명언`
명언 |
------+
최인규는천재|
select concat(name, " ", grade) AS `직원` from tStaff ts ;
직원 |
-------+
강감찬 사원 |
김유신 이사 |
논개 대리 |
대조영 차장 |
선덕여왕 사원|
성삼문 대리 |
신사임당 부장|
안중근 대리 |
안창호 사원 |
유관순 과장 |
윤봉길 과장 |
을지문덕 사원|
이사부 대리 |
이율곡 과장 |
장보고 부장 |
정몽주 대리 |
정약용 과장 |
허난설헌 사원|
홍길동 차장 |
황진이 사원 |
SQL
복사
•
중복 제거
select region from tCity;
=== 이전 ===
region|
------+
경상 |
서울 |
전라 |
경기 |
전라 |
충청 |
강원 |
강원 |
=== distinct 적용 후 ===
region|
------+
경상 |
서울 |
전라 |
경기 |
충청 |
강원 |
SQL
복사
•
정렬
◦
SELECT 문에서 순서에 대한 지정이 없는 경우에는 DBMS의 순서를 따른다.
(Oracle은 데이터의 입력 순서, MySQL은 기본키에 대한 오름차순 정렬)
◦
기본형식 : ORDER BY 컬럼명 [ASC | DESC]
◦
오름차순인 경우에는 ASC, 내림차순인 경우에는 DESC를 지정한다.
◦
기본값은 ASC로 생략이 가능하다.
◦
오름차순 :
▪
숫자는 작은 값이 먼저 조회
▪
날짜는 빠른 값이 먼저 조회
▪
문자는 알파벳 순서, 가나다 순서 조회
▪
NULL 값은 제일 나중에 조회
## 정렬 (ORDER BY)
select * from tCity order by region;
name|area|popu|metro|region|
----+----+----+-----+------+
춘천 |1116| 27|n |강원 |
홍천 |1819| 7|n |강원 |
오산 | 42| 21|n |경기 |
부산 | 765| 342|y |경상 |
서울 | 605| 974|y |서울 |
순천 | 910| 27|n |전라 |
전주 | 205| 65|n |전라 |
청주 | 940| 83|n |충청 |
select * from tCity order by area;
name|area|popu|metro|region|
----+----+----+-----+------+
오산 | 42| 21|n |경기 |
전주 | 205| 65|n |전라 |
서울 | 605| 974|y |서울 |
부산 | 765| 342|y |경상 |
순천 | 910| 27|n |전라 |
청주 | 940| 83|n |충청 |
춘천 |1116| 27|n |강원 |
홍천 |1819| 7|n |강원 |
select * from tCity order by popu;
name|area|popu|metro|region|
----+----+----+-----+------+
홍천 |1819| 7|n |강원 |
오산 | 42| 21|n |경기 |
순천 | 910| 27|n |전라 |
춘천 |1116| 27|n |강원 |
전주 | 205| 65|n |전라 |
청주 | 940| 83|n |충청 |
부산 | 765| 342|y |경상 |
서울 | 605| 974|y |서울 |
select * from tCity order by popu DESC;
name|area|popu|metro|region|
----+----+----+-----+------+
서울 | 605| 974|y |서울 |
부산 | 765| 342|y |경상 |
청주 | 940| 83|n |충청 |
전주 | 205| 65|n |전라 |
순천 | 910| 27|n |전라 |
춘천 |1116| 27|n |강원 |
오산 | 42| 21|n |경기 |
홍천 |1819| 7|n |강원 |
select * from tCity order by popu DESC, region;
name|area|popu|metro|region|
----+----+----+-----+------+
서울 | 605| 974|y |서울 |
부산 | 765| 342|y |경상 |
청주 | 940| 83|n |충청 |
전주 | 205| 65|n |전라 |
춘천 |1116| 27|n |강원 |
순천 | 910| 27|n |전라 |
오산 | 42| 21|n |경기 |
홍천 |1819| 7|n |강원 |
SQL
복사
•
정렬 실습
# 인구수로 오름차순 정렬
SELECT * FROM tCity ORDER BY popu;
name|area|popu|metro|region|
----+----+----+-----+------+
홍천 |1819| 7|n |강원 |
오산 | 42| 21|n |경기 |
순천 | 910| 27|n |전라 |
춘천 |1116| 27|n |강원 |
전주 | 205| 65|n |전라 |
청주 | 940| 83|n |충청 |
부산 | 765| 342|y |경상 |
서울 | 605| 974|y |서울 |
SQL
복사
# 5번째 컬럼 오름차순, 첫번째 컬럼 내림차순
SELECT * FROM tCity
ORDER BY 5, 1 DESC;
name|area|popu|metro|region|
----+----+----+-----+------+
홍천 |1819| 7|n |강원 |
춘천 |1116| 27|n |강원 |
오산 | 42| 21|n |경기 |
부산 | 765| 342|y |경상 |
서울 | 605| 974|y |서울 |
전주 | 205| 65|n |전라 |
순천 | 910| 27|n |전라 |
청주 | 940| 83|n |충청 |
# 에러 발생
SELECT name AS `도시명`, popu AS `인구`
FROM tCity tc ORDER BY 5, 1 DESC;
SQL
복사
# 인구수로 내림차순 정렬
SELECT * FROM tCity ORDER BY popu DESC;
name|area|popu|metro|region|
----+----+----+-----+------+
서울 | 605| 974|y |서울 |
부산 | 765| 342|y |경상 |
청주 | 940| 83|n |충청 |
전주 | 205| 65|n |전라 |
순천 | 910| 27|n |전라 |
춘천 |1116| 27|n |강원 |
오산 | 42| 21|n |경기 |
홍천 |1819| 7|n |강원 |
SQL
복사
# 지역명 오름차순 + 도시명 내림차순 정렬
SELECT * FROM tCity ORDER BY region, name DESC;
name|area|popu|metro|region|
----+----+----+-----+------+
홍천 |1819| 7|n |강원 |
춘천 |1116| 27|n |강원 |
오산 | 42| 21|n |경기 |
부산 | 765| 342|y |경상 |
서울 | 605| 974|y |서울 |
전주 | 205| 65|n |전라 |
순천 | 910| 27|n |전라 |
청주 | 940| 83|n |충청 |
SQL
복사
# 인구 수 내림차순 정렬
SELECT name AS `도시명`, popu AS `인구` FROM tCity tc ORDER BY `인구` DESC;
도시명|인구 |
---+---+
서울 |974|
부산 |342|
청주 | 83|
전주 | 65|
순천 | 27|
춘천 | 27|
오산 | 21|
홍천 | 7|
SQL
복사
# tstaff 테이블에서 salary가 적은 사람부터 순서대로 출력하되,
# salary가 같다면 score가 높은 사람을 먼저 조회
select * from tstaff order by salary, score;
SQL
복사
•
조건문
◦
WHERE 절을 이용해 조건을 지정할 수 있다. WHERE 절은 SELECT 문 뿐만 아니라 삭제를 위한 DELETE, 수정을 위한 UPDATE 절에도 쓰인다.
SELECT * FROM 테이블명 WHERE 조건식;
###########################################################################
metro = 'y';
region <> '전라';
area > 1000;
popu <= 100;
score IS NULL;
score IS NOT NULL;
SQL
복사
•
비교 연산자
A = B
A > B, A < B
A >= B, NOT (A < B)
A <= B, NOT (A > B)
A <> B, A != B, NOT (A = B) [같지 않다]
# 문자열 또는 날짜의 비교는 따옴표로 감싸주어야 한다.
SQL
복사
•
where
# tcity 테이블에서 metro가 n인 데이터 조회 (name, popu 컬럼만 조회)
select name, popu from tCity where metro = 'n' order by popu desc;
name|popu|
----+----+
청주 | 83|
전주 | 65|
순천 | 27|
춘천 | 27|
오산 | 21|
홍천 | 7|
SQL
복사
# tstaff 테이블에서 joindate가 2015년 이전인 데이터 조회 (name, depart, grade 컬럼만 조회)
select * from tStaff;
select name, depart, grade from tStaff where joindate < '2016-01-01'
select name, depart, grade from tStaff where DATE_FORMAT(joindate, '%Y') <= 2015;
name|depart|grade|
----+------+-----+
김유신 |총무부 |이사 |
논개 |인사과 |대리 |
성삼문 |영업부 |대리 |
신사임당|영업부 |부장 |
안중근 |인사과 |대리 |
안창호 |영업부 |사원 |
유관순 |영업부 |과장 |
윤봉길 |영업부 |과장 |
이사부 |총무부 |대리 |
장보고 |인사과 |부장 |
정몽주 |총무부 |대리 |
황진이 |인사과 |사원 |
SQL
복사
•
NULL: 값이 입력되어 있지 않은 특수한 상태
◦
값을 알 수 없거나, 아직 결정할 수 없다는 의미이다.
◦
NULL 여부를 표현할 때는 = NULL, != NULL 이 아닌 IS NULL, IS NOT NULL을 사용한다.
# NULL은 비교할 때, IS 또는 IS NOT을 사용한다.
SELECT * FROM tstaff WHERE score IS NULL;
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
유관순 |영업부 |여 |2009-03-01|과장 | 380| |
을지문덕|영업부 |남 |2019-06-29|사원 | 330| |
SELECT * FROM tstaff WHERE score IS NOT NULL;
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80|
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50|
SQL
복사
•
논리 연산자
select * from logic_operation lo ;
a|b|and |or |
-+-+------+-----+
0|0| | |
0|1| |OR 부합|
1|0| |OR 부합|
1|1|AND 부합|OR 부합|
select `a`, `b`, `and` FROM logic_operation lo where a = 1 and b = 1;
a|b|and |
-+-+------+
1|1|AND 부합|
select `a`, `b`, `and` FROM logic_operation lo where a = 1 or b = 1;
a|b|and |
-+-+------+
0|1| |
1|0| |
1|1|AND 부합|
select `a` from logic_operation lo where not a = 1;
a|
-+
0|
0|
SQL
복사
# tstaff 테이블에서 salary가 300 미만이면서 score는 60 이상인 직원이 누구인지 조회
select *
from tStaff ts ;
select *
from tStaff ts where salary < 300 and score >= 60;
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
SQL
복사
# tstaff 테이블에서 인사과 남자 직원과 영업부 여자 직원을 모두 조회
select *
from tStaff ts
where (depart = "인사과" and gender = "남")
or (depart = "영업부" and gender = "여");
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
유관순 |영업부 |여 |2009-03-01|과장 | 380| |
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|
SQL
복사
•
LIKE
◦
등호(=)를 통한 비교 연산은 완전히 일치하는 조건식을 표현하는데 비해, LIKE 연산자는 와일드 카드를 사용한 패턴으로 부분 문자열을 검색
•
와일드카드
◦
‘%’: 길이에 구애받지 않는 임의의 문자열
◦
_ : 한 개의 임의 문자
◦
와일드카드에 사용되는 문자를 검색할 때는 \또는 ESCAPE를 이용
# emp 테이블에서 'T'이라는 글자가 들어가는 직원을 검색
select * from emp;
select * from emp where ENAME LIKE '%T%';
# emp 테이블에서 이름에 'T'라는 글자가 들어가지 않는 직원을 검색
select * from emp where ENAME NOT LIKE '%T%';
# emp 테이블에서 이름이 'T'로 끝나는 직원을 검색
select * from emp where ENAME LIKE '%T';
# emp 테이블에시 이름이 'T'로 시작하는 직원을 검색
select * from emp where ENAME LIKE 'T%';
# promotion_tbl 테이블에서 promotion_msg에 '30%' 라는 글자가 들어가는 상품 검색
select * from promotion_tbl pt where promotion_msg LIKE '%30=%%' ESCAPE '=';
select * from promotion_tbl pt where promotion_msg LIKE '%30\%%';
SQL
복사
•
BETWEEN ~ AND
SELECT * FROM tCity WHERE popu BETWEEN 50 AND 100;
name|area|popu|metro|region|
----+----+----+-----+------+
전주 | 205| 65|n |전라 |
청주 | 940| 83|n |충청 |
SELECT * FROM tCity WHERE popu >= 50 AND popu <= 100;
name|area|popu|metro|region|
----+----+----+-----+------+
전주 | 205| 65|n |전라 |
청주 | 940| 83|n |충청 |
SELECT * FROM tStaff WHERE name BETWEEN '가' AND '사';
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|
SELECT * FROM tStaff WHERE joindate BETWEEN '20150101' AND '20180101';
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
SQL
복사
•
IN
◦
IN 연산자는 불연속적인 값 여러 개의 목록을 가지고,
목록에 요소와 일치하는 데이터를 조회한다.
◦
NOT과 결합해서 사용 가능하다.
SELECT * FROM tcity WHERE region IN ('경상', '전라');
name|area|popu|metro|region|
----+----+----+-----+------+
부산 | 765| 342|y |경상 |
순천 | 910| 27|n |전라 |
전주 | 205| 65|n |전라 |
SELECT * FROM tcity WHERE region = '경상' OR region = '전라';
name|area|popu|metro|region|
----+----+----+-----+------+
부산 | 765| 342|y |경상 |
순천 | 910| 27|n |전라 |
전주 | 205| 65|n |전라 |
SQL
복사
•
IN, LIKE 실습
# tcity 테이블에서 area가 500~1000 사이의 도시 목록을 조회
select * from tCity tc ;
select * from tCity tc where area BETWEEN 500 and 1000;
select * from tCity tc where area >= 500 and area <= 1000;
name|area|popu|metro|region|
----+----+----+-----+------+
부산 | 765| 342|y |경상 |
서울 | 605| 974|y |서울 |
순천 | 910| 27|n |전라 |
청주 | 940| 83|n |충청 |
# tcity 테이블에서 region 필드가 경상 또는 전라가 아닌 모든 도시를 조회
select * from tCity tc where region NOT IN ('경상', '전라')
select * from tCity tc where region != '경상' AND region != '전라'
name|area|popu|metro|region|
----+----+----+-----+------+
서울 | 605| 974|y |서울 |
오산 | 42| 21|n |경기 |
청주 | 940| 83|n |충청 |
춘천 |1116| 27|n |강원 |
홍천 |1819| 7|n |강원 |
# tstaff 테이블에서 성이 '이'씨 이거나 '안'씨인 직원을 조회
select * from tStaff;
select * from tStaff where name LIKE '이%' or name LIKE '안%';
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
# tstaff 테이블에서 총무부나 영업부에 근무하는 직원을 조회
select * from tStaff ts where depart IN ("총무부", "영업부");
select * from tStaff ts where depart = "총무부" or depart = "영업부";
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|
유관순 |영업부 |여 |2009-03-01|과장 | 380| |
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| |
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80|
# tstaff 테이블에서 인사과나 영업부에 근무하는 대리를 조회
select * from tStaff ts where (depart in ('인사과', '영업부')) and grade = '대리';
select * from tStaff ts where (depart = '인사과' or depart = '영업부') and grade = '대리';
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
SQL
복사
•
행의 개수 제한
◦
SELECT 문 맨 뒤에 LIMIT를 작성하여 행의 개수를 제한할 수 있다.
◦
MySQL에서는 LIMIT를 이용하지만, ORACLE에서는 ROWNUM이라는 개념을 이용하고,
MS-SQL에서는 TOP를 이용한다.
◦
기본 형식 : LIMIT [건너뛸 개수,] 조회할 개수, 건너뛸 개수를 생략하면 0이 기본값이다.
SELECT * FROM tcity ORDER BY area DESC LIMIT 4;=> 4개를 가져옴
select * from tcity order by area DESC LIMIT 0, 4; => 0번째부터 4개를 가져옴
SQL
복사
# 행의 개수 제한 - LIMIT [건너뛸개수,] 조회할개수
select * from tcity order by area;
select * from tcity order by area DESC LIMIT 0, 4;
name|area|popu|metro|region|
----+----+----+-----+------+
홍천 |1819| 7|n |강원 |
춘천 |1116| 27|n |강원 |
청주 | 940| 83|n |충청 |
순천 | 910| 27|n |전라 |
select * from tcity order by area DESC LIMIT 1, 4;
name|area|popu|metro|region|
----+----+----+-----+------+
춘천 |1116| 27|n |강원 |
청주 | 940| 83|n |충청 |
순천 | 910| 27|n |전라 |
부산 | 765| 342|y |경상 |
SQL
복사
# tstaff 테이블에서 salary가 높은 상위 5명의 직원을 조회
select * from tStaff ts order by salary desc limit 5;
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
유관순 |영업부 |여 |2009-03-01|과장 | 380| |
# tcity 테이블에서 area가 넓은 도시 중 앞의 2개는 건너뛰고 이후 3개의 도시를 조회
select * from tCity tc order by area desc ;
select * from tCity tc order by area desc limit 2, 3;
select * from tCity tc order by area desc limit 3 OFFSET 2;
name|area|popu|metro|region|
----+----+----+-----+------+
청주 | 940| 83|n |충청 |
순천 | 910| 27|n |전라 |
부산 | 765| 342|y |경상 |
# tstaff 테이블에서 salary 순으로 내림차순 정렬한 후 12위에서 16위까지 조회
select * from tStaff ts2 order by salary desc;
select * from tStaff ts order by salary desc limit 11, 5
select * from tStaff ts order by salary desc limit 5 OFFSET 11;
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| |
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|
SQL
복사
수치 연산
순서: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
# WHERE 구에서 연산하기
SELECT * FROM tcity WHERE popu * 10000 / area < 1000;
name|area|popu|metro|region|
----+----+----+-----+------+
순천 | 910| 27|n |전라 |
청주 | 940| 83|n |충청 |
춘천 |1116| 27|n |강원 |
홍천 |1819| 7|n |강원 |
SELECT *, (popu * 10000 / area < 1000) `인구밀도`
FROM tCity tc
WHERE (popu * 10000 / area) <= 1000;
name|area|popu|metro|region|인구밀도|
----+----+----+-----+------+----+
순천 | 910| 27|n |전라 | 1|
청주 | 940| 83|n |충청 | 1|
춘천 |1116| 27|n |강원 | 1|
홍천 |1819| 7|n |강원 | 1|
SELECT *, (popu * 10000 / area < 1000) `인구밀도`
FROM tCity tc
WHERE `인구밀도` <= 1000;
=> 오류 발생, 인구밀도 라는 변수를 찾을 수 없음
# ORDER BY 구에서 연산하기
SELECT *
FROM tCity tc
ORDER BY (popu * 10000 / area) desc;
name|area|popu|metro|region|
----+----+----+-----+------+
서울 | 605| 974|y |서울 |
오산 | 42| 21|n |경기 |
부산 | 765| 342|y |경상 |
전주 | 205| 65|n |전라 |
청주 | 940| 83|n |충청 |
순천 | 910| 27|n |전라 |
춘천 |1116| 27|n |강원 |
홍천 |1819| 7|n |강원 |
SELECT *, (popu * 10000 / area) `인구밀도`
FROM tCity tc
ORDER BY `인구밀도` DESC;
name|area|popu|metro|region|인구밀도 |
----+----+----+-----+------+----------+
서울 | 605| 974|y |서울 |16099.1736|
오산 | 42| 21|n |경기 | 5000.0000|
부산 | 765| 342|y |경상 | 4470.5882|
전주 | 205| 65|n |전라 | 3170.7317|
청주 | 940| 83|n |충청 | 882.9787|
순천 | 910| 27|n |전라 | 296.7033|
춘천 |1116| 27|n |강원 | 241.9355|
홍천 |1819| 7|n |강원 | 38.4827|
SQL
복사
•
NULL과 하는 모든 연산은 NULL이다.
# NULL과 하는 모든 연산은 NULL이다.
SELECT
NULL * 1,
NULL + 1,
NULL - 1,
1 - NULL,
NULL / 1,
1 / NULL,
NULL * NULL,
NULL + NULL,
NULL - NULL,
NULL / NULL;
NULL * 1|NULL + 1|NULL - 1|1 - NULL|NULL / 1|1 / NULL|NULL * NULL|NULL + NULL|NULL - NULL|NULL / NULL|
--------+--------+--------+--------+--------+--------+-----------+-----------+-----------+-----------+
| | | | | | | | | |
SQL
복사
함수
•
산술 함수
ABS(x): 인수 x의 절대값을 반환
CEILING(x): x보다 크거나 같은 최소 정수를 반환
FLOOR(x): x보다 작거나 같은 최대 정수를 반환
ROUND(x): x를 가장 가까운 정수로 반올림
CONV(x, y, z): x를 y진수에서 z 진수로 변환
PI(): 원주율 π 값을 반환
MOD(x, y): x를 y로 나눈 나머지를 반환
POW(x, y): x의 y 거듭제곱 값을 반환
SQRT(x): x의 제곱근을 반환
RAND(): 0과 1 사이의 무작위 숫자를 반환
SIGN(x): x가 양수면 1, 음수면 -1, 0이면 0을 반환
TRUNC(x): x의 소수점 이하를 잘라내어 정수 부분만 반환
SQL
복사
SELECT
10 % 3 AS `연산자 나머지 연산`,
MOD (10, 3) AS `함수 나머지 연산`;
연산자 나머지 연산|함수 나머지 연산|
------+-----+
1| 1|
SELECT
10 % 3 AS `연산자 나머지 연산`,
MOD (10, 3) AS `함수 나머지 연산`,
ROUND(10.5);
연산자 나머지 연산|함수 나머지 연산|ROUND(10.5)|
------+-----+-----------+
1| 1| 11|
# 반올림
SELECT
10 % 3 AS `연산자 나머지 연산`,
MOD (10, 3) AS `함수 나머지 연산`,
ROUND(10.5),
round(3.1415926, 3) `반올림`,
round(3141.5926, -3) `반올림`;
연산자 나머지 연산|함수 나머지 연산|ROUND(10.5)|반올림 |반올림 |
----------+---------+-----------+-----+----+
1| 1| 11|3.142|3000|
SQL
복사
SELECT
10 % 3 AS `연산자 나머지 연산`,
MOD (10, 3) AS `함수 나머지 연산`,
ROUND(10.5),
round(3.1415926, 3) `반올림`,
round(3141.5926, -3) `반올림`,
TRUNCATE(10.5, 0) `버림`,
TRUNCATE(3.1415926, 3) `버림`,
TRUNCATE(3141.5926, -3) `버림`;
SQL
복사

select name, score, TRUNCATE(score, 0) % 2 AS `홀짝` from tStaff ts ;
select name, score, MOD(TRUNCATE(score, 0), 2) AS `홀짝` from tStaff ts ;
SELECT name, score, MOD(FLOOR(score), 2) `홀짝` from tStaff ts;
name|score|홀짝|
----+-----+--+
강감찬 |56.00| 0|
김유신 |88.80| 0|
논개 |46.20| 0|
대조영 |49.90| 1|
선덕여왕|45.10| 1|
성삼문 |87.75| 1|
신사임당|92.00| 0|
안중근 |76.50| 0|
안창호 |74.20| 0|
유관순 | | |
윤봉길 |71.25| 1|
을지문덕| | |
이사부 |50.00| 0|
이율곡 |65.40| 1|
장보고 |58.30| 0|
정몽주 |89.50| 1|
정약용 |69.80| 1|
허난설헌|44.50| 0|
홍길동 |77.70| 1|
황진이 |52.50| 0|
SQL
복사
# emp 테이블에서 EMPNO가 홀수인 데이터의 모든 컬럼을 조회
select * from emp;
select * from emp where mod(empno, 2) = 1;
select * from emp where (empno % 2) = 1;
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM |DEPTNO|
-----+-----+---------+----+----------+------+-----+------+
7369|SMITH|CLERK |7902|1980-12-17| 800.0| | 20|
7499|ALLEN|SALESMAN |7698|1981-02-20|1600.0|300.0| 30|
7521|WARD |SALESMAN |7698|1981-02-22|1250.0|500.0| 30|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
SQL
복사
# tstaff 테이블에서 score 소수점 첫째자리에서 반올림하여 데이터를 조회
select *, ROUND(score) FROM tStaff ts ;
select name, depart, gender, joindate, grade, salary, score, ROUND(score) `new_score`
from tStaff;
name|depart|gender|joindate |grade|salary|score|new_score|
----+------+------+----------+-----+------+-----+---------+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00| 56|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80| 89|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20| 46|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90| 50|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10| 45|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75| 88|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00| 92|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50| 77|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20| 74|
유관순 |영업부 |여 |2009-03-01|과장 | 380| | |
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25| 71|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| | |
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00| 50|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40| 65|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30| 58|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50| 90|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80| 70|
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50| 45|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70| 78|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50| 53|
SQL
복사
•
문자열 함수
LENGTH(str): 문자열의 길이를 문자 수로 반환
CONCAT(str1, str2, ...): 여러 문자열을 결합하여 하나의 문자열로 반환
CONCAT_WS(separator, str1, str2, ...): 여러 문자열을 결합하여 하나의 문자열로 반환
INSTR(str, substr), LOCATE(substr, str): 문자열에서 서브 문자열의 위치를 찾아 반환
REPEAT(str, count): 문자열을 지정된 횟수만큼 반복하여 반환
REPLACE(str, oldstr, newstr): 문자열에서 oldstr을 newstr로 모두 치환
REVERSE(str): 문자열을 뒤집어 반환
UPPER(str), LOWER(str): 문자열을 대문자 또는 소문자로 변환
LTRIM(str), RTRIM(str), TRIM(str): 문자열의 왼쪽, 오른쪽, 또는 양쪽의 공백을 제거
LEFT(str, len), RIGHT(str, len): 문자열의 왼쪽 또는 오른쪽에서 len만큼의 문자를 반환
SUBSTRING(str, start, length) : 문자열에서 일부를 추출 (start는 1부터 시작)
SQL
복사
•
문자열 결합 함수 (CONCAT)


# usertbl 테이블에서 name과 name의 길이를 조회
select name, LENGTH(name) / 3 from usertbl u ;
name|LENGTH(name) / 3|
----+----------------+
에일리 | 3.0000|
배주현 | 3.0000|
배수지 | 3.0000|
구하라 | 3.0000|
아이유 | 3.0000|
전소미 | 3.0000|
김설현 | 3.0000|
김태연 | 3.0000|
이효리 | 3.0000|
산다라박| 4.0000|
select hiredate,
SUBSTRING(hiredate, 1, 4) AS '연도',
SUBSTRING(hiredate, 6, 2) AS '월' from emp;
hiredate |연도 |월 |
----------+----+--+
1980-12-17|1980|12|
1981-02-20|1981|02|
1981-02-22|1981|02|
1981-04-02|1981|04|
1981-09-28|1981|09|
1981-05-01|1981|05|
1981-06-09|1981|06|
1987-07-13|1987|07|
1981-11-17|1981|11|
1981-09-08|1981|09|
1987-07-13|1987|07|
1981-12-03|1981|12|
1981-12-03|1981|12|
1982-01-23|1982|01|
select name, CONCAT(FLOOR(LENGTH(name) / 3), "글자") `name의 길이` FROM usertbl;
name|name의 길이|
----+--------+
에일리 |3글자 |
배주현 |3글자 |
배수지 |3글자 |
구하라 |3글자 |
아이유 |3글자 |
전소미 |3글자 |
김설현 |3글자 |
김태연 |3글자 |
이효리 |3글자 |
산다라박|4글자 |
SQL
복사
•
날짜 함수
ADDDATE(date, INTERVAL expr unit) : 지정된 날짜(date)에 특정 기간(expr unit)을 더함
SUBDATE(date, INTERVAL expr unit) : 지정된 날짜(date)에 특정 기간(expr unit)을 뺌
ADDTIME(time, INTERVAL expr unit) : 지정된 시간(time)에 특정 기간(expr unit)을 더함
SUBTIME(time, INTERVAL expr unit): 지정된 시간(time)에 특정 기간(expr unit)을 뺌
CURRENT_DATE(), CURDATE(): 현재 날짜를 반환
CURRENT_TIME(), CURTIME(): 현재 시간을 반환
NOW(), LOCALTIME(), LOCALTIMESTAMP(), CURRENT_TIMESTAMP(): 현재 날짜와 시간을 반환
YEAR(date), MONTH(date), DAY(date) : 주어진 날짜에서 각각의 구성 요소를 반환
HOUR(time), MINUTE(time), SECOND(time), 주어진 시간에서 각각의 구성 요소를 반환
DAYOFWEEK(date): 주어진 날짜의 요일을 반환 (1 = 일요일, 2 = 월요일, ..., 7 = 토요일)
QUARTER(date): 주어진 날짜의 분기(quarter)를 반환
STR_TO_DATE(str, format): 문자열로 표시된 날짜를 날짜 형식으로 변환
DATEDIFF(date1, date2): 두 날짜 사이의 일 수 차이를 반환
TIMEDIFF(time1, time2): 두 시간 사이의 시간 차이를 반환
LAST_DAY(date): 주어진 날짜의 해당 월의 마지막 날짜를 반환
SQL
복사
# tstaff 테이블에서 오늘 날짜까지 입사 후 며칠이 지났는지 조회
select *, DATEDIFF(CURRENT_DATE(), joindate) AS '일수' from tStaff ts ;
name|depart|gender|joindate |grade|salary|score|일수 |
----+------+------+----------+-----+------+-----+----+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|2117|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|8940|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|5062|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|1480|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10|2549|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|3701|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|4055|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|4465|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|3268|
유관순 |영업부 |여 |2009-03-01|과장 | 380| |5626|
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|3268|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| |1854|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00|8940|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|3062|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|7056|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50|5062|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80|1595|
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50|1664|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|1814|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50|4465|
# usertbl 테이블에서 birthyear와 mdate 컬럼을 사용해, 만 나이 조회
select
name,
YEAR(CURDATE()) - birthyear - (RIGHT(CURDATE(), 5) <= RIGHT(mdate, 5))
from usertbl;
name|YEAR(CURDATE()) - birthyear - (RIGHT(CURDATE(), 5) <= RIGHT(mdate, 5))|
----+----------------------------------------------------------------------+
에일리 | 35|
배주현 | 33|
배수지 | 29|
구하라 | 33|
아이유 | 31|
전소미 | 23|
김설현 | 29|
김태연 | 35|
이효리 | 45|
산다라박| 39|
SQL
복사
•
NULL 관련 함수
IFNULL(x, y) : x 값이 NULL이 아니면 x를 반환하고, x 값이 NULL이면 y를 반환
NULLIF(x, y) : x 값과 y 값이 같으면 NULL을 반환하고, 다르면 x를 반환
COALESCE(x, y, z, …) : 인자 값들 중 최초 NULL이 아닌 값을 반환, 모두 NULL이면 NULL 반환
SQL
복사
•
제어 흐름 함수
IF 함수 : 수식이 참 또는 거짓인지 결과에 따라서 2중 분기
SELECT IF(10 > 20, '참', '거짓');
CASE ~ WHEN ~ ELSE ~ END 연산
SELECT
CASE 10
WHEN 1 THEN '일'
WHEN 5 THEN '오'
WHEN 10 THEN '십'
ELSE '모름'
END;
SQL
복사
# tstaff 테이블에서 salary가 300이상이면 salary의 30%
# 그렇지 않으면 salary의 50%로 계산한 성과급 칼럼을 추가하여 데이터 조회
SELECT *,
IF (salary > 300, salary * 0.3, salary * 0.5) AS `성과급`, name
from tStaff ts ;
name|depart|gender|joindate |grade|salary|score|성과급 |name|
----+------+------+----------+-----+------+-----+-----+----+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00| 96.0|강감찬 |
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|126.0|김유신 |
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|102.0|논개 |
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|145.0|대조영 |
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10| 94.5|선덕여왕
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|142.5|성삼문 |
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|120.0|신사임당
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|128.0|안중근 |
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|111.0|안창호 |
유관순 |영업부 |여 |2009-03-01|과장 | 380| |114.0|유관순 |
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|105.0|윤봉길 |
을지문덕|영업부 |남 |2019-06-29|사원 | 330| | 99.0|을지문덕
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00|112.5|이사부 |
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|115.5|이율곡 |
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|132.0|장보고 |
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50|111.0|정몽주 |
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80|114.0|정약용 |
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50|142.5|허난설헌
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|114.0|홍길동 |
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50|137.5|황진이 |
# tstaff 테이블에서 grade가 사원이면 100, 대리이면 200, 나머지는 300으로 성과급 칼럼을 가하여 데이터 조회
SELECT *,
IF (grade = "사원", 100, IF(grade = '대리', 200, 300))
AS `성과급`,
name from tStaff ts;
SQL
복사