

함수
•
함수
◦
제어 흐름 함수
▪
IF 함수: 수식이 참 또는 거짓인지 결과에 따라서 2중 분기
SELECT IF(10 > 20, '참', '거짓');
SQL
복사
▪
CASE ~ WHEN ~ ELSE ~ END 연산
CASE ~ WHEN ~ ELSE ~ END 연산
SELECT
CASE 10
WHEN 1 THEN '일'
WHEN 5 THEN '오'
WHEN 10 THEN '십'
ELSE '모름'
END;
SQL
복사
CASE
•
CASE문
- 조건에 따른 값을 지정하기 위해 사용한다.
- 기존 연산자와 함수로 처리가 불가능한 것들을 간단하게 처리할 수 있다.
- ‘검색 CASE’ 와 ‘단순 CASE’로 나눌 수 있다.
SELECT
CASE 10
when 1 then '일'
when 5 then '오'
when 10 then '십'
else '모름'
end `CASE 연산`;
CASE 연산|
-------+
십 |
SQL
복사
•
CASE 활용 사례
SELECT
*,
CASE
WHEN score IS NULL THEN 0
ELSE score
END
FROM tstaff;
name|depart|gender|joindate |grade|salary|score|ifnull(score, 0)|
----+------+------+----------+-----+------+-----+----------------+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00| 56.00|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80| 88.80|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20| 46.20|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90| 49.90|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10| 45.10|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75| 87.75|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00| 92.00|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50| 76.50|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20| 74.20|
유관순 |영업부 |여 |2009-03-01|과장 | 380| | 0.00|
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25| 71.25|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| | 0.00|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00| 50.00|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40| 65.40|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30| 58.30|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50| 89.50|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80| 69.80|
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50| 44.50|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70| 77.70|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50| 52.50|
SELECT
*
,
IFNULL(score, 0)
FROM tstaff;
name|depart|gender|joindate |grade|salary|score|ifnull(score, 0)|
----+------+------+----------+-----+------+-----+----------------+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00| 56.00|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80| 88.80|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20| 46.20|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90| 49.90|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10| 45.10|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75| 87.75|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00| 92.00|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50| 76.50|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20| 74.20|
유관순 |영업부 |여 |2009-03-01|과장 | 380| | 0.00|
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25| 71.25|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| | 0.00|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00| 50.00|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40| 65.40|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30| 58.30|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50| 89.50|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80| 69.80|
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50| 44.50|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70| 77.70|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50| 52.50|
SQL
복사
# tstaff 테이블에서 gender가 '남'인 경우, 1로 바꾸어 출력
# '여'인 경우, 2로 바꾸어 출력 `성별` 컬럼 추가해서 출력
select * ,
case gender
when '남' then 1
when '여' then 2
else 0
end as `성별`
from
tStaff ts ;
name|depart|gender|joindate |grade|salary|score|성별|
----+------+------+----------+-----+------+-----+--+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00| 1|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80| 1|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20| 2|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90| 1|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10| 2|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75| 1|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00| 2|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50| 1|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20| 1|
유관순 |영업부 |여 |2009-03-01|과장 | 380| | 2|
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25| 1|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| | 1|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00| 1|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40| 1|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30| 1|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50| 1|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80| 1|
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50| 2|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70| 1|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50| 2|
SQL
복사
•
CASE와 where, order by 활용
SELECT *
FROM tstaff
WHERE
CASE grade
WHEN '사원' THEN 1
WHEN '대리' THEN 2
WHEN '차장' THEN 3
WHEN '과장' THEN 4
WHEN '부장' THEN 5
WHEN '이사' THEN 6
ELSE NULL
END = 6;
SQL
복사
SELECT *
FROM tstaff
ORDER BY
CASE grade
WHEN '사원' THEN 1
WHEN '대리' THEN 2
WHEN '차장' THEN 3
WHEN '과장' THEN 4
WHEN '부장' THEN 5
WHEN '이사' THEN 6
ELSE NULL
END;
SQL
복사
SELECT
* FROM tstaff
WHERE
case grade
when '사원' THEN 1
when '대리' then 2
when '차장' then 3
when '과장' then 4
when '부장' then 5
when '이사' then 6
else null
end in (1, 6);
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| |
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50|
SQL
복사
SELECT
* FROM tstaff
WHERE
case grade
when '사원' THEN 1
when '대리' then 2
when '차장' then 3
when '과장' then 4
when '부장' then 5
when '이사' then 6
else null
end BETWEEN 3 and 6;
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|
유관순 |영업부 |여 |2009-03-01|과장 | 380| |
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|
SQL
복사
select *
from tStaff ts
order by
case grade
when '사원' THEN 1
when '대리' then 2
when '차장' then 3
when '과장' then 4
when '부장' then 5
when '이사' then 6
else null
end
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10|
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| |
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|
유관순 |영업부 |여 |2009-03-01|과장 | 380| |
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
select *
from tStaff ts
order by
case grade
when '사원' THEN 1
when '대리' then 2
when '차장' then 3
when '과장' then 4
when '부장' then 5
when '이사' then 6
else null
end desc,
salary;
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
김유신 |총무부 |남 |2000-02-03|이사 | 420|88.80|
신사임당|영업부 |여 |2013-06-19|부장 | 400|92.00|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|
윤봉길 |영업부 |남 |2015-08-15|과장 | 350|71.25|
유관순 |영업부 |여 |2009-03-01|과장 | 380| |
정약용 |총무부 |남 |2020-03-14|과장 | 380|69.80|
이율곡 |총무부 |남 |2016-03-08|과장 | 385|65.40|
대조영 |총무부 |남 |2020-07-07|차장 | 290|49.90|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
성삼문 |영업부 |남 |2014-06-08|대리 | 285|87.75|
논개 |인사과 |여 |2010-09-16|대리 | 340|46.20|
정몽주 |총무부 |남 |2010-09-16|대리 | 370|89.50|
이사부 |총무부 |남 |2000-02-03|대리 | 375|50.00|
황진이 |인사과 |여 |2012-05-05|사원 | 275|52.50|
허난설헌|인사과 |여 |2020-01-05|사원 | 285|44.50|
선덕여왕|인사과 |여 |2017-08-03|사원 | 315|45.10|
강감찬 |영업부 |남 |2018-10-09|사원 | 320|56.00|
을지문덕|영업부 |남 |2019-06-29|사원 | 330| |
안창호 |영업부 |남 |2015-08-15|사원 | 370|74.20|
SQL
복사
GROUP BY
•
집계함수는 그룹화와 함께 사용되어, SELECT 문의 활용범위를 넓힐 수 있다.
GROUP BY구에는 그룹화할 열을 지정하며, 복수의 컬럼 지정도 가능하다.
SELECT grade, AVG(salary) AS `직급별 평균 임금`
FROM tstaff
GROUP BY grade
ORDER BY `직급별 평균 임금` ASC;
grade|직급별 평균 임금|
-----+---------+
사원 | 315.8333|
대리 | 325.2000|
차장 | 335.0000|
과장 | 373.7500|
이사 | 420.0000|
부장 | 420.0000|
SELECT depart, gender, COUNT(*)
FROM tStaff
GROUP BY depart, gender
ORDER BY depart, gender;
depart|gender|COUNT(*)|
------+------+--------+
영업부 |남 | 5|
영업부 |여 | 2|
인사과 |남 | 3|
인사과 |여 | 4|
총무부 |남 | 6|
SELECT depart, CONCAT(COUNT(*), "명") `부서, 성별 직원 수`
FROM tStaff ts
GROUP BY depart, gender
ORDER BY depart, gender;
depart|부서, 성별 직원 수|
------+-----------+
영업부 |5명 |
영업부 |2명 |
인사과 |3명 |
인사과 |4명 |
총무부 |6명 |
SQL
복사
데이터 집계
•
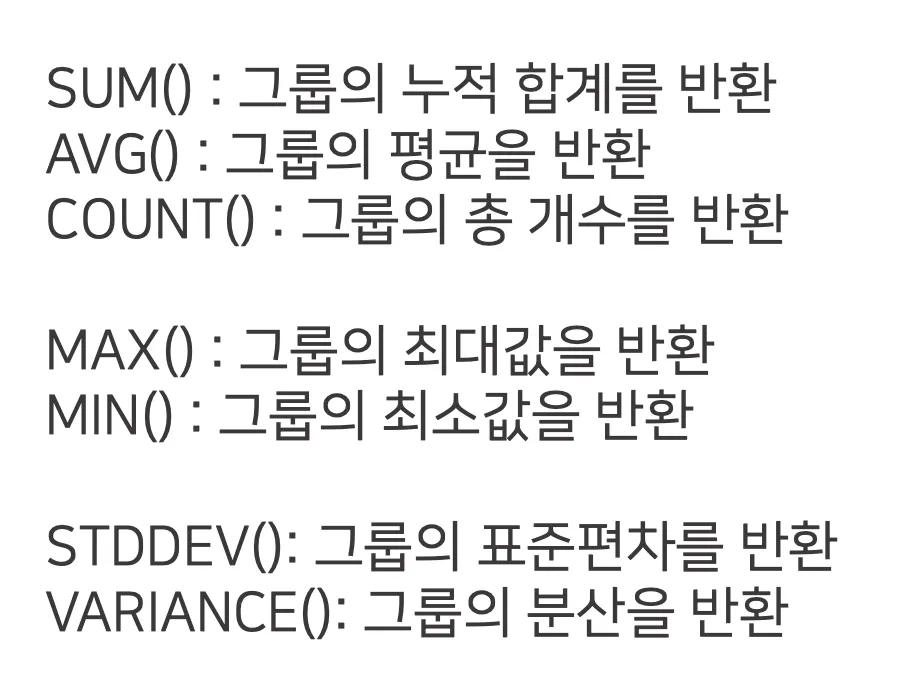
집계함수: 복수의 값에서 하나의 값을 계산하는 함수
◦
데이터를 그룹화해서 통계를 계산해주는 함수로 숫자나 날짜 데이터에 사용된다.
문자열 데이터는 최소값과 최대값 조회만 가능하다.
•
SUM
◦
수치형 데이터 합계 계산
•
AVG
◦
수치형 데이터 평균 계산
•
COUNT
◦
주어진 집합의 ‘개수’를 구해 반환
•
MIN, MAX
◦
MIN 함수와 MAX 함수는 집합에서 최소값과 최대값을 구함
SELECT addr, SUM(mdate)
FROM usertbl u
GROUP BY addr ;
addr|SUM(mdate)|
----+----------+
미국 | 19890530|
대구 | 19910329|
광주 | 39851123|
서울 | 39721029|
캐나다 | 20010309|
부천 | 19950103|
전주 | 19890309|
부산 | 19841112|
SELECT addr, SUM(mdate), AVG(mdate), MAX(mdate), MIN(mdate)
FROM usertbl u
GROUP BY addr ;
addr|SUM(mdate)|AVG(mdate) |MAX(mdate)|MIN(mdate)|
----+----------+-------------+----------+----------+
미국 | 19890530|19890530.0000|1989-05-30|1989-05-30|
대구 | 19910329|19910329.0000|1991-03-29|1991-03-29|
광주 | 39851123|19925561.5000|1994-10-10|1991-01-13|
서울 | 39721029|19860514.5000|1993-05-19|1979-05-10|
캐나다 | 20010309|20010309.0000|2001-03-09|2001-03-09|
부천 | 19950103|19950103.0000|1995-01-03|1995-01-03|
전주 | 19890309|19890309.0000|1989-03-09|1989-03-09|
부산 | 19841112|19841112.0000|1984-11-12|1984-11-12|
SELECT addr, COUNT(*), SUM(mdate), AVG(mdate), MAX(mdate), MIN(mdate)
FROM usertbl u
GROUP BY addr;
addr|COUNT(*)|SUM(mdate)|AVG(mdate) |MAX(mdate)|MIN(mdate)|
----+--------+----------+-------------+----------+----------+
미국 | 1| 19890530|19890530.0000|1989-05-30|1989-05-30|
대구 | 1| 19910329|19910329.0000|1991-03-29|1991-03-29|
광주 | 2| 39851123|19925561.5000|1994-10-10|1991-01-13|
서울 | 2| 39721029|19860514.5000|1993-05-19|1979-05-10|
캐나다 | 1| 20010309|20010309.0000|2001-03-09|2001-03-09|
부천 | 1| 19950103|19950103.0000|1995-01-03|1995-01-03|
전주 | 1| 19890309|19890309.0000|1989-03-09|1989-03-09|
부산 | 1| 19841112|19841112.0000|1984-11-12|1984-11-12|
SQL
복사
•
실습
-- tstaff 테이블이 가진 데이터 개수(총 직원수) 조회
select count(*) from tStaff ts;
count(*)|
--------+
20|
-- tstaff 테이블에서 급여가 400 이상인 직원 수 조회
select count(* ) `급여가 400 이상` from tStaff ts where salary >= 400;
급여가 400 이상|
----------+
3|
-- tstaff 테이블에서 직급별 직원수 조회
select grade, count(*) from tStaff ts group by grade;
grade|count(*)|
-----+--------+
사원 | 6|
이사 | 1|
대리 | 5|
차장 | 2|
부장 | 2|
과장 | 4|
-- 이사 제외
select grade, count(*), AVG(salary) from tStaff ts
where grade <> '이사'
group by grade;
grade|count(*)|AVG(salary)|
-----+--------+-----------+
사원 | 6| 315.8333|
대리 | 5| 325.2000|
차장 | 2| 335.0000|
부장 | 2| 420.0000|
과장 | 4| 373.7500|
-- tstaff 테이블에서 직급 종류 개수 조회
select * from tStaff ts2 ;
select count(DISTINCT GRADE) from tStaff;
count(DISTINCT GRADE)|
---------------------+
6|
-- tstaff 테이블에서 score 값이 없는 직원 수 조회
select * from tStaff ts;
select count(*) from tStaff ts where score is null;
select count(*) - count(score) from tStaff;
count(*)|
--------+
2|
-- tstaff 테이블에서 인사과의 평균 급여 조회
select * from tStaff ts ;
select avg(salary) as '인사과 평균' from tStaff ts where depart = '인사과';
사과 평균 |
-------+
27.2857|
-- tcity 테이블에서 인구의 총합과 평균을 조회
select * from tCity tc2 ;
select sum(popu) AS '인구의 총합', avg(popu) AS '인구의 평균' from tCity tc;
인구의 총합|인구의 평균 |
------+--------+
1546|193.2500|
-- tcity 테이블에서 면적의 최소값과 최대값을 조회
select * from tCity tc;
select min(area), max(area) from tCity tc;
min(area)|max(area)|
---------+---------+
42| 1819|
SQL
복사
HAVING
•
HAVING:
GROUP BY와 함께 쓰이며, 출력할 그룹의 조건을 지정한다.
-- HAVING: GROUP BY와 함께 쓰이며, 출력할 그룹의 조건을 지정한다.
SELECT
depart, AVG(salary)
FROM tStaff ts
GROUP BY depart
HAVING AVG(salary) >= 350;
depart|AVG(salary)|
------+-----------+
총무부 | 370.0000|
SQL
복사

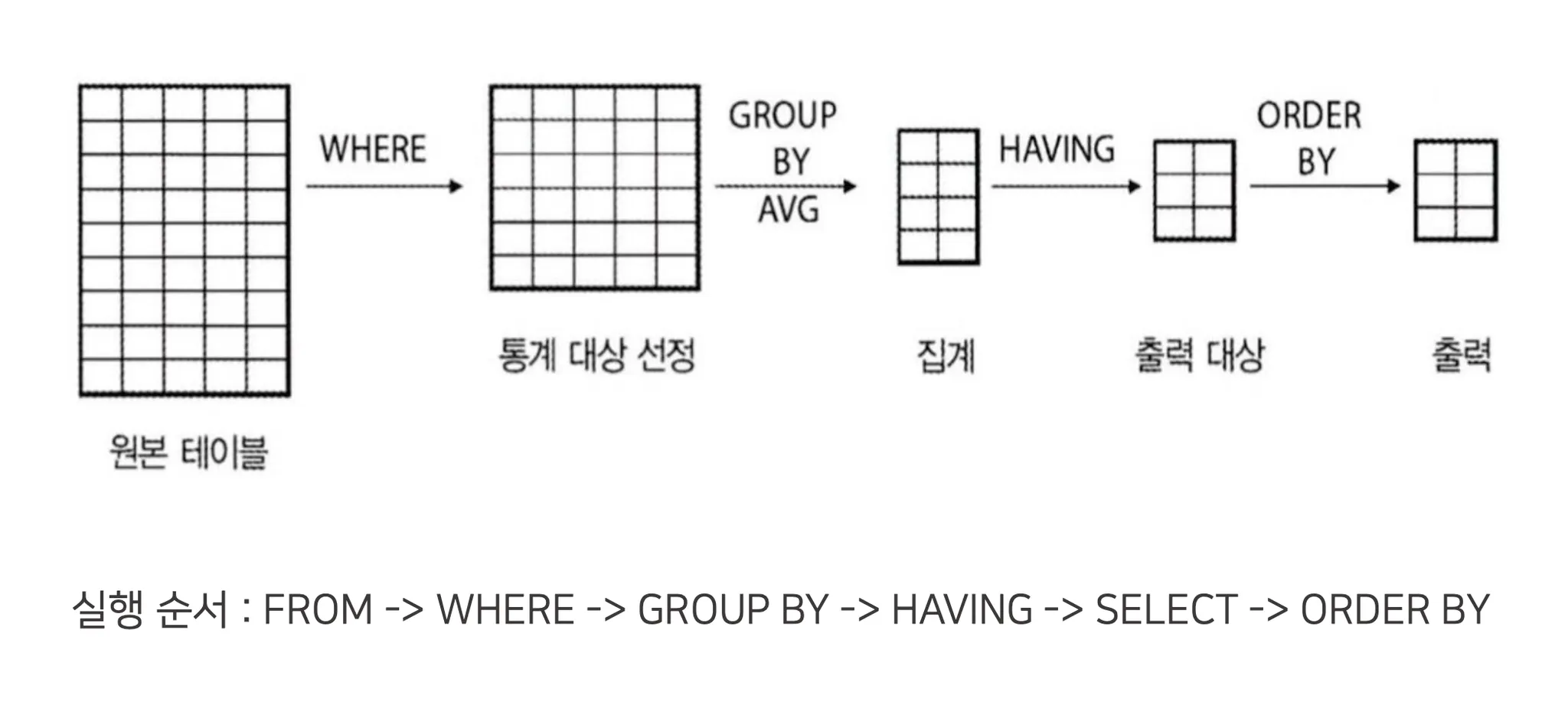
select 문 실행되는 과정
2개 이상의 테이블로부터 데이터 추출하는 방법
•
집합 연산자를 이용하는 방법
•
서브쿼리를 이용하는 방법

•
조인을 이용하는 방법
집합 연산자
•
집합 연산자를 활용하면, 2개 이상의 SELECT 문을 연결하여 작성 가능하다.
◦
SELECT 문의 컬럼 개수와 데이터 타입은 일치해야 한다.
◦
검색 결과의 헤더는 앞쪽 SELECT 문에 의해 결정된다.
◦
ORDER BY 절을 사용할 때는 문장의 제일 마지막에 사용한다.
SELECT ...
FROM 테이블명 ...
UNION | UNION ALL | INTERSECT | MINUS
SELECT ...
FROM 테이블명 ...
[ORDER BY [열이름] [ASC | DESC]];
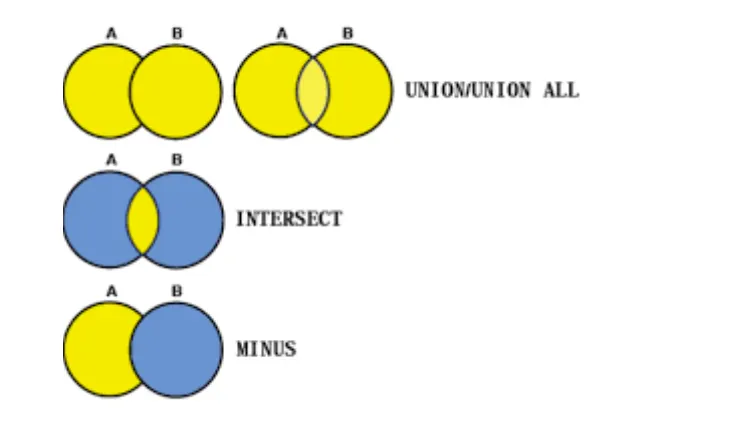
• UNION : 합집합 (중복되는 값은 한번 출력)
• UNION ALL : 합집합 (중복되는 값 모두 출력)
• INTERSECT : 교집합
• EXCEPT : 차집합 (다른 DBMS에서 MINUS)
SQL
복사
SELECT DEPTNO FROM DEPT
UNION
SELECT DEPTNO FROM EMP; -- 4개 (중복 제거된 합집합)
DEPTNO|
------+
10|
20|
30|
40|
SELECT DEPTNO FROM emp
UNION ALL
SELECT DEPTNO FROM dept; -- 18개 (중복 포함하는 합집합)
DEPTNO|
------+
10|
10|
10|
20|
20|
20|
20|
20|
30|
30|
30|
30|
30|
30|
10|
20|
30|
40|
SELECT DEPTNO FROM emp
INTERSECT
SELECT DEPTNO FROM dept;
DEPTNO|
------+
20|
30|
10|
-- 차집합: 순서에 유의하자 --
SELECT DEPTNO FROM dept
EXCEPT
SELECT DEPTNO FROM emp;
DEPTNO|
------+
40|
SQL
복사
서브 쿼리 (Sub Query)
•
하나의 SQL 문 안에 포함되어 있는 SQL 문을 의미하며,
메인 쿼리가 서브 쿼리를 포함하는 종속적인 관계이다.
• 항상 Main Query의 기준으로 결과를 나타낸다.
• Sub Query는 반드시 괄호로 감싸서 사용한다.
• Sub Query는 Main Query 실행 전에 한 번 실행된다.
• Sub Query에서 ORDER BY 절은 사용 불가하다.
• FROM 절에 Sub Query를 사용하는 것을 ‘인라인 뷰’라 한다.
SQL
복사
•
단일 행(Single Row) 서브 쿼리
◦
수행 결과가 오직 하나의 데이터(행, row) 만을 반환하는 SubQuery
◦
인구의 최대값을 먼저 조회한 뒤, 인구 수가 최대값과 동일한 데이터조회
// 서울 출력
SELECT name
FROM tCity
WHERE popu = (
SELECT MAX(popu) FROM tCity
);
name|
----+
서울 |
SQL
복사
•
서브 쿼리 예제
-- EMP 테이블을 이용해 평균 급여보다 더 많은 급여를 받는 사원을 검색 (단일 행 서브쿼리)
select * from emp where sal > (
select avg(sal) from emp
);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+---------+----+----------+------+----+------+
7566|JONES|MANAGER |7839|1981-04-02|2975.0| | 20|
7698|BLAKE|MANAGER |7839|1981-05-01|2850.0| | 30|
7782|CLARK|MANAGER |7839|1981-06-09|2450.0| | 10|
7788|SCOTT|ANALYST |7566|1987-07-13|3000.0| | 20|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
-- EMP 테이블에서 MILLER와 같은 부서(deptno)에서 근무하는 사원을 검색 (단일 행 서브쿼리)
select * from emp where DEPTNO = (
select DEPTNO from emp where ename = 'MILLER'
);
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+------+---------+----+----------+------+----+------+
7782|CLARK |MANAGER |7839|1981-06-09|2450.0| | 10|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7934|MILLER|CLERK |7782|1982-01-23|1300.0| | 10|
-- EMP 테이블에서 MILLER와 동일한 job을 가진 사원을 검색 (단일 행 서브쿼리)
select * from emp where JOB = (
select job from emp where ename = 'MILLER'
);
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+------+-----+----+----------+------+----+------+
7369|SMITH |CLERK|7902|1980-12-17| 800.0| | 20|
7876|ADAMS |CLERK|7788|1987-07-13|1100.0| | 20|
7900|JAMES |CLERK|7698|1981-12-03| 950.0| | 30|
7934|MILLER|CLERK|7782|1982-01-23|1300.0| | 10|
-- EMP 테이블에서 MILLER와 급여(SAL)와 동일하거나 더 많이 받는 사원을 검색 (단일 행 서브쿼리)
select * from emp where sal >= (
select sal emp where ename = 'MILLER'
);
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+------+-----+----+----------+------+----+------+
7934|MILLER|CLERK|7782|1982-01-23|1300.0| | 10|
-- EMP 테이블에서 deptno을 이용해 LOC가 DALLAS인 사원 검색 (DEPT 테이블 활용), (단일 행 서브쿼리)
SELECT * from emp where DEPTNO = (
select DEPTNO from dept where loc = 'DALLAS'
);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+-------+----+----------+------+----+------+
7369|SMITH|CLERK |7902|1980-12-17| 800.0| | 20|
7566|JONES|MANAGER|7839|1981-04-02|2975.0| | 20|
7788|SCOTT|ANALYST|7566|1987-07-13|3000.0| | 20|
7876|ADAMS|CLERK |7788|1987-07-13|1100.0| | 20|
7902|FORD |ANALYST|7566|1981-12-03|3000.0| | 20|
-- EMP 테이블에서 직속상관(MGR)의 이름이 KING인 사원 검색 (단일 행 서브쿼리)
select * from emp;
select * from emp where mgr = (
select empno from emp where ename = 'KING'
);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+-------+----+----------+------+----+------+
7566|JONES|MANAGER|7839|1981-04-02|2975.0| | 20|
7698|BLAKE|MANAGER|7839|1981-05-01|2850.0| | 30|
7782|CLARK|MANAGER|7839|1981-06-09|2450.0| | 10|
-- 안중근과 같은 부서에 근무하고 성별이 같은 직원의 모든 정보 조회 (다중 열 서브쿼리)
select *
from tStaff ts
where (depart, gender) =
(
select depart, gender from tStaff ts where name = '안중근'
);
name|depart|gender|joindate |grade|salary|score|
----+------+------+----------+-----+------+-----+
안중근 |인사과 |남 |2012-05-05|대리 | 256|76.50|
장보고 |인사과 |남 |2005-04-01|부장 | 440|58.30|
홍길동 |인사과 |남 |2019-08-08|차장 | 380|77.70|
SQL
복사
•
다중 행 서브쿼리
◦
SubQuery에서 반환되는 결과가 하나 이상의 행일 때 사용
◦
다중 행 서브 쿼리는 다중 행 연산자와 함께 사용
# EMP 테이블에서 부서(deptno)별로 가장 급여를 많이 받는 사원들과
# 동일한 급여를 받는 사원 검색
select max(sal) from emp where sal in (
select MAX(sal)
from emp
group by DEPTNO
);
max(sal)|
--------+
5000.0|
# ALL (서브쿼리 결과 모두 일치하면 참)
SELECT * FROM emp WHERE sal > ALL (
SELECT sal FROM emp WHERE DEPTNO = 30
);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+---------+----+----------+------+----+------+
7566|JONES|MANAGER |7839|1981-04-02|2975.0| | 20|
7788|SCOTT|ANALYST |7566|1987-07-13|3000.0| | 20|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
-- 30번 부서의 급여에서 급여의 최소값보다 큰 직원 조회
SELECT * FROM emp WHERE sal > ANY (
SELECT sal FROM emp where DEPTNO = 30
);
SELECT * FROM emp WHERE sal > (
SELECT MIN(sal) FROM emp WHERE DEPTNO = 30
);
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM |DEPTNO|
-----+------+---------+----+----------+------+------+------+
7499|ALLEN |SALESMAN |7698|1981-02-20|1600.0| 300.0| 30|
7521|WARD |SALESMAN |7698|1981-02-22|1250.0| 500.0| 30|
7566|JONES |MANAGER |7839|1981-04-02|2975.0| | 20|
7654|MARTIN|SALESMAN |7698|1981-09-28|1250.0|1400.0| 30|
7698|BLAKE |MANAGER |7839|1981-05-01|2850.0| | 30|
7782|CLARK |MANAGER |7839|1981-06-09|2450.0| | 10|
7788|SCOTT |ANALYST |7566|1987-07-13|3000.0| | 20|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7844|TURNER|SALESMAN |7698|1981-09-08|1500.0| 0.0| 30|
7876|ADAMS |CLERK |7788|1987-07-13|1100.0| | 20|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
7934|MILLER|CLERK |7782|1982-01-23|1300.0| | 10|
-- 30번 부서의 급여에서 급여의 최대값보다 큰 직원 조회
SELECT * FROM emp WHERE sal > (
SELECT MAX(sal) FROM emp WHERE DEPTNO = 30
);
SELECT * FROM emp WHERE sal > ALL (
SELECT sal FROM emp WHERE DEPTNO = 30
);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+---------+----+----------+------+----+------+
7566|JONES|MANAGER |7839|1981-04-02|2975.0| | 20|
7788|SCOTT|ANALYST |7566|1987-07-13|3000.0| | 20|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
# EXIST - (데이터 존재 여부 확인)
# sal이 2000 넘는 직원이 있으면, 모든 직원 조회
select * from emp where EXISTS (
select * from emp where sal > 2000
);
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM |DEPTNO|
-----+------+---------+----+----------+------+------+------+
7369|SMITH |CLERK |7902|1980-12-17| 800.0| | 20|
7499|ALLEN |SALESMAN |7698|1981-02-20|1600.0| 300.0| 30|
7521|WARD |SALESMAN |7698|1981-02-22|1250.0| 500.0| 30|
7566|JONES |MANAGER |7839|1981-04-02|2975.0| | 20|
7654|MARTIN|SALESMAN |7698|1981-09-28|1250.0|1400.0| 30|
7698|BLAKE |MANAGER |7839|1981-05-01|2850.0| | 30|
7782|CLARK |MANAGER |7839|1981-06-09|2450.0| | 10|
7788|SCOTT |ANALYST |7566|1987-07-13|3000.0| | 20|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7844|TURNER|SALESMAN |7698|1981-09-08|1500.0| 0.0| 30|
7876|ADAMS |CLERK |7788|1987-07-13|1100.0| | 20|
7900|JAMES |CLERK |7698|1981-12-03| 950.0| | 30|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
7934|MILLER|CLERK |7782|1982-01-23|1300.0| | 10|
SQL
복사
•
실습 코드
-- EMP 테이블에서 부서별로 가장 급여를 많이 받는 사원들과 동일한 급여를 받는 사원 검색
select * from emp where sal in(
select max(sal)
from emp
group by DEPTNO);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+---------+----+----------+------+----+------+
7698|BLAKE|MANAGER |7839|1981-05-01|2850.0| | 30|
7788|SCOTT|ANALYST |7566|1987-07-13|3000.0| | 20|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
-- EMP 테이블에서 SAL를 3,000 이상 받는 사원이 소속된 부서와 동일한 부서에서 근무하는 사원 검색
select * from emp where deptno IN (
select DISTINCT DEPTNO from emp where sal >= 3000
);
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+------+---------+----+----------+------+----+------+
7369|SMITH |CLERK |7902|1980-12-17| 800.0| | 20|
7566|JONES |MANAGER |7839|1981-04-02|2975.0| | 20|
7782|CLARK |MANAGER |7839|1981-06-09|2450.0| | 10|
7788|SCOTT |ANALYST |7566|1987-07-13|3000.0| | 20|
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7876|ADAMS |CLERK |7788|1987-07-13|1100.0| | 20|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
7934|MILLER|CLERK |7782|1982-01-23|1300.0| | 10|
-- EMP 테이블에서 JOB이 MANAGER인 사람이 속한 부서 정보 검색
select * from dept where deptno in (
select DISTINCT deptno from emp where job = 'MANAGER'
);
DEPTNO|DNAME |LOC |
------+----------+--------+
10|ACCOUNTING|NEW YORK|
20|RESEARCH |DALLAS |
30|SALES |CHICAGO |
-- EMP 테이블에서 BLAKE와 동일한 부서에 있는 모든 사원 검색
select * from emp where DEPTNO = (
select DEPTNO from emp where ename = 'blake'
);
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM |DEPTNO|
-----+------+--------+----+----------+------+------+------+
7499|ALLEN |SALESMAN|7698|1981-02-20|1600.0| 300.0| 30|
7521|WARD |SALESMAN|7698|1981-02-22|1250.0| 500.0| 30|
7654|MARTIN|SALESMAN|7698|1981-09-28|1250.0|1400.0| 30|
7698|BLAKE |MANAGER |7839|1981-05-01|2850.0| | 30|
7844|TURNER|SALESMAN|7698|1981-09-08|1500.0| 0.0| 30|
7900|JAMES |CLERK |7698|1981-12-03| 950.0| | 30|
-- EMP 테이블에서 평균 급여(SAL) 이상을 받는 모든 사원 검색. 급여가 많은 순으로 출력
select * from emp where sal >= (
select avg(sal) from emp
)
order by sal desc;
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+---------+----+----------+------+----+------+
7839|KING |PRESIDENT| |1981-11-17|5000.0| | 10|
7788|SCOTT|ANALYST |7566|1987-07-13|3000.0| | 20|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
7566|JONES|MANAGER |7839|1981-04-02|2975.0| | 20|
7698|BLAKE|MANAGER |7839|1981-05-01|2850.0| | 30|
7782|CLARK|MANAGER |7839|1981-06-09|2450.0| | 10|
-- EMP 테이블에서 이름에 “T”가 있는 사원이 근무하는 부서에서 있는 모든 사원 검색. 사원번호 순으로 출력
select * from emp where DEPTNO IN (
select DISTINCT DEPTNO from emp where ename LIKE '%T%'
)
order by EMPNO;
EMPNO|ENAME |JOB |MGR |HIREDATE |SAL |COMM |DEPTNO|
-----+------+--------+----+----------+------+------+------+
7369|SMITH |CLERK |7902|1980-12-17| 800.0| | 20|
7499|ALLEN |SALESMAN|7698|1981-02-20|1600.0| 300.0| 30|
7521|WARD |SALESMAN|7698|1981-02-22|1250.0| 500.0| 30|
7566|JONES |MANAGER |7839|1981-04-02|2975.0| | 20|
7654|MARTIN|SALESMAN|7698|1981-09-28|1250.0|1400.0| 30|
7698|BLAKE |MANAGER |7839|1981-05-01|2850.0| | 30|
7788|SCOTT |ANALYST |7566|1987-07-13|3000.0| | 20|
7844|TURNER|SALESMAN|7698|1981-09-08|1500.0| 0.0| 30|
7876|ADAMS |CLERK |7788|1987-07-13|1100.0| | 20|
7900|JAMES |CLERK |7698|1981-12-03| 950.0| | 30|
7902|FORD |ANALYST |7566|1981-12-03|3000.0| | 20|
-- EMP 테이블에서 근무 지역이 DALLAS인 사원 정보 검색
select * from emp where DEPTNO IN (
select DEPTNO from dept where loc = "DALLAS"
);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+-------+----+----------+------+----+------+
7369|SMITH|CLERK |7902|1980-12-17| 800.0| | 20|
7566|JONES|MANAGER|7839|1981-04-02|2975.0| | 20|
7788|SCOTT|ANALYST|7566|1987-07-13|3000.0| | 20|
7876|ADAMS|CLERK |7788|1987-07-13|1100.0| | 20|
7902|FORD |ANALYST|7566|1981-12-03|3000.0| | 20|
-- EMP 테이블에서 MGR의 이름이 KING인 사원 검색
select * from emp where mgr = (
select empno from emp where ename = 'KING'
);
EMPNO|ENAME|JOB |MGR |HIREDATE |SAL |COMM|DEPTNO|
-----+-----+-------+----+----------+------+----+------+
7566|JONES|MANAGER|7839|1981-04-02|2975.0| | 20|
7698|BLAKE|MANAGER|7839|1981-05-01|2850.0| | 30|
7782|CLARK|MANAGER|7839|1981-06-09|2450.0| | 10|
SQL
복사
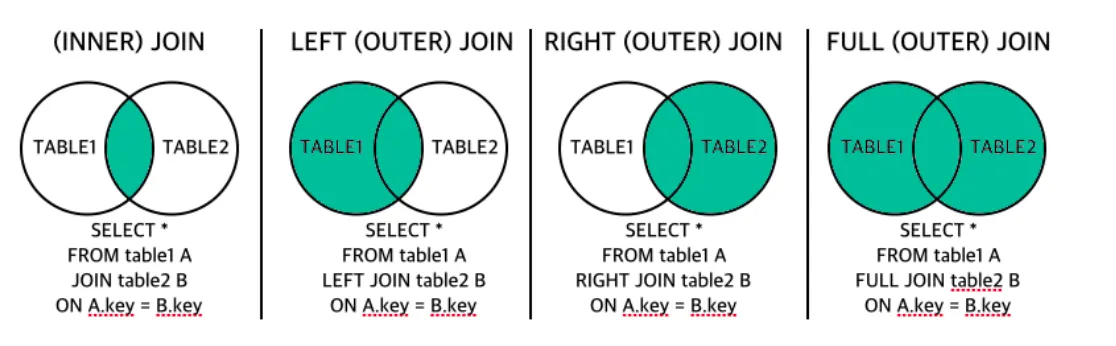
JOIN
•
두 개의 테이블을 엮어서 원하는 결과를 가져오고자 할 때 사용
•
CROSS JOIN - 2개 테이블의 모든 집합의 JOIN
◦
조인 결과의 전체 행 개수는 두 테이블의 각 행의 개수를 곱한 수이고,
이를 카티션 곱(CARTESIAN PRODUCT)이라 한다.
# JOIN (2개 이상의 테이블을 엮어서 데이터를 조회)
SELECT * FROM tcar, tmaker; # Join
select * from tcar cross join tmaker;
car|capacity|price|maker|maker|factory|domestic|
---+--------+-----+-----+-----+-------+--------+
소나타| 2000| 2500|현대 |기아 |서울 |y |
소나타| 2000| 2500|현대 |Audi |독일 |n |
소나타| 2000| 2500|현대 |쌍용 |청주 |y |
소나타| 2000| 2500|현대 |현대 |부산 |y |
그랜저| 2500| 3500|현대 |기아 |서울 |y |
그랜저| 2500| 3500|현대 |Audi |독일 |n |
그랜저| 2500| 3500|현대 |쌍용 |청주 |y |
그랜저| 2500| 3500|현대 |현대 |부산 |y |
티볼리| 1600| 2300|쌍용 |기아 |서울 |y |
티볼리| 1600| 2300|쌍용 |Audi |독일 |n |
티볼리| 1600| 2300|쌍용 |쌍용 |청주 |y |
티볼리| 1600| 2300|쌍용 |현대 |부산 |y |
코란도| 1800| 3000|쌍용 |기아 |서울 |y |
코란도| 1800| 3000|쌍용 |Audi |독일 |n |
코란도| 1800| 3000|쌍용 |쌍용 |청주 |y |
코란도| 1800| 3000|쌍용 |현대 |부산 |y |
A8 | 3000| 4800|Audi |기아 |서울 |y |
A8 | 3000| 4800|Audi |Audi |독일 |n |
A8 | 3000| 4800|Audi |쌍용 |청주 |y |
A8 | 3000| 4800|Audi |현대 |부산 |y |
SM5| 2000| 2600|삼성 |기아 |서울 |y |
SM5| 2000| 2600|삼성 |Audi |독일 |n |
SM5| 2000| 2600|삼성 |쌍용 |청주 |y |
-- 테이블명도 별명을 지을 수 있다
SELECT c.maker, m.maker FROM tcar c CROSS JOIN tmaker m;
maker|maker|
-----+-----+
현대 |기아 |
현대 |Audi |
현대 |쌍용 |
현대 |현대 |
현대 |기아 |
현대 |Audi |
현대 |쌍용 |
현대 |현대 |
쌍용 |기아 |
쌍용 |Audi |
쌍용 |쌍용 |
쌍용 |현대 |
쌍용 |기아 |
쌍용 |Audi |
쌍용 |쌍용 |
쌍용 |현대 |
Audi |기아 |
Audi |Audi |
Audi |쌍용 |
Audi |현대 |
삼성 |기아 |
삼성 |Audi |
삼성 |쌍용 |
삼성 |현대 |
select * from tcar, tmaker where tcar.maker = tmaker.maker;
car|capacity|price|maker|maker|factory|domestic|
---+--------+-----+-----+-----+-------+--------+
소나타| 2000| 2500|현대 |현대 |부산 |y |
그랜저| 2500| 3500|현대 |현대 |부산 |y |
티볼리| 1600| 2300|쌍용 |쌍용 |청주 |y |
코란도| 1800| 3000|쌍용 |쌍용 |청주 |y |
A8 | 3000| 4800|Audi |Audi |독일 |n |
-- JOIN에서 WHERE절은 테이블 별명을 붙인 후에는 WHERE 절에서는 별명을 사용하는 것이 필수!
select * from tcar CROSS JOIN tmaker WHERE tcar.maker = tmaker.maker;
select * from tcar AS c CROSS JOIN tmaker m WHERE c.maker = m.maker;
car|capacity|price|maker|maker|factory|domestic|
---+--------+-----+-----+-----+-------+--------+
소나타| 2000| 2500|현대 |현대 |부산 |y |
그랜저| 2500| 3500|현대 |현대 |부산 |y |
티볼리| 1600| 2300|쌍용 |쌍용 |청주 |y |
코란도| 1800| 3000|쌍용 |쌍용 |청주 |y |
A8 | 3000| 4800|Audi |Audi |독일 |n |
SQL
복사
•
INNER JOIN - 두 테이블의 공통된 컬럼의 데이터를 활용한 조인
◦
INNER JOIN - 값이 있는 것들만 가져옴
◦
LEFT JOIN - 값이 없는 것들도 가져옴
SELECT * FROM tcar INNER JOIN tmaker ON tcar.maker = tmaker.maker;
SELECT * FROM tcar c INNER JOIN tmaker m ON c.maker = m.maker;
car|capacity|price|maker|maker|factory|domestic|
---+--------+-----+-----+-----+-------+--------+
소나타| 2000| 2500|현대 |현대 |부산 |y |
그랜저| 2500| 3500|현대 |현대 |부산 |y |
티볼리| 1600| 2300|쌍용 |쌍용 |청주 |y |
코란도| 1800| 3000|쌍용 |쌍용 |청주 |y |
A8 | 3000| 4800|Audi |Audi |독일 |n |
SELECT c.*, m.* FROM tcar c INNER JOIN tmaker m ON c.maker = m.maker;
car|capacity|price|maker|maker|factory|domestic|
---+--------+-----+-----+-----+-------+--------+
소나타| 2000| 2500|현대 |현대 |부산 |y |
그랜저| 2500| 3500|현대 |현대 |부산 |y |
티볼리| 1600| 2300|쌍용 |쌍용 |청주 |y |
코란도| 1800| 3000|쌍용 |쌍용 |청주 |y |
A8 | 3000| 4800|Audi |Audi |독일 |n |
SQL
복사
•
NATURAL JOIN (문법) - 컬럼명이 동일한 경우
select * from tcar join tmaker using (maker);
maker|car|capacity|price|factory|domestic|
-----+---+--------+-----+-------+--------+
현대 |소나타| 2000| 2500|부산 |y |
현대 |그랜저| 2500| 3500|부산 |y |
쌍용 |티볼리| 1600| 2300|청주 |y |
쌍용 |코란도| 1800| 3000|청주 |y |
Audi |A8 | 3000| 4800|독일 |n |
SQL
복사
•
SELF JOIN (구조)
SELECT CONCAT(e.ename, "의 매니저는 ", m.ename)
FROM emp e, emp m
where e.MGR = m.EMPNO;
SELECT CONCAT(e.ename, "의 매니저는 ", m.ename) FROM emp e join emp m on e.MGR = m.EMPNO;
CONCAT(e.ename, "의 매니저는 ", m.ename)|
-----------------------------------+
SMITH의 매니저는 FORD |
ALLEN의 매니저는 BLAKE |
WARD의 매니저는 BLAKE |
JONES의 매니저는 KING |
MARTIN의 매니저는 BLAKE |
BLAKE의 매니저는 KING |
CLARK의 매니저는 KING |
SCOTT의 매니저는 JONES |
TURNER의 매니저는 BLAKE |
ADAMS의 매니저는 SCOTT |
JAMES의 매니저는 BLAKE |
FORD의 매니저는 JONES |
MILLER의 매니저는 CLARK |
SQL
복사
•
Subquery, INNER JOIN 비교
-- DEPT 테이블의 LOC가 'NEW YORK' 인 사원의 이름과 급여 조회
-- 서브 쿼리
select ename, sal from emp where DEPTNO = (
select DISTINCT deptno from dept where LOC = 'NEW YORK');
-- JOIN 활용 --
select e.ename, e.sal
from emp e
JOIN dept d ON e.DEPTNO = d.DEPTNO
where d.loc = 'NEW YORK';
ename |sal |
------+------+
CLARK |2450.0|
KING |5000.0|
MILLER|1300.0|
SQL
복사
•
INNER JOIN 실습
-- DEPT 테이블의 DNAME 컬럼의 값이 ‘ACCOUNTING’ 인 사원의 EMP 테이블의 이름과 입사일을 조회
select e.ename, e.hiredate
from emp e
JOIN dept d
ON e.DEPTNO = d.DEPTNO
where d.DNAME = 'ACCOUNTING';
ename |hiredate |
------+----------+
CLARK |1981-06-09|
KING |1981-11-17|
MILLER|1982-01-23|
-- EMP 테이블의 JOB이 ‘MANAGER’인 사원의 EMP 테이블의 이름, DEPT 테이블의 부서명을 조회
select e.ename, d.dname from emp e JOIN dept d
ON e.DEPTNO = d.DEPTNO
where e.job = 'MANAGER';
ename|dname |
-----+----------+
JONES|RESEARCH |
BLAKE|SALES |
CLARK|ACCOUNTING|
-- EMP 테이블와 SALGRADE 테이블을 이용해 각 급여에 해당하는 등급을 매핑하여, 이름, 급여, 등급을 조회
select e.ename '이름', e.sal '급여', sg.GRADE '등급'
from emp e
JOIN SALGRADE sg
ON e.sal > sg.LOSAL
and e.sal < sg.HISAL;
select e.ename '이름', e.sal '급여', sg.GRADE '등급'
from emp e
JOIN SALGRADE sg
ON e.sal BETWEEN sg.LOSAL
and sg.HISAL;
이름 |급여 |등급|
------+------+--+
SMITH | 800.0| 1|
ALLEN |1600.0| 3|
WARD |1250.0| 2|
JONES |2975.0| 4|
MARTIN|1250.0| 2|
BLAKE |2850.0| 4|
CLARK |2450.0| 4|
KING |5000.0| 5|
TURNER|1500.0| 3|
ADAMS |1100.0| 1|
JAMES | 950.0| 1|
MILLER|1300.0| 2|
-- EMP 테이블에서 MANAGER 가 ‘KING’인 사원들의 이름, 직급을 조회
select e.ename, e.job
from emp e
join emp m on e.mgr = m.EMPNO
where m.ename = 'KING';
ename|job |
-----+-------+
JONES|MANAGER|
BLAKE|MANAGER|
CLARK|MANAGER|
SQL
복사
•
OUTER JOIN - JOIN 조건에서 한쪽 값이 없더라도 행을 반환
◦
만약 한쪽 테이블에는 데이터가 존재하는데,
다른 쪽 테이블에는 해당 데이터가 존재하지 않을 경우 그 데이터는 출력되지 않는다.
◦
해당 문제점을 해결하기 위해 사용하는 조인 기법이 OUTER JOIN이다.
SELECT CONCAT(e.ename, "의 매니저는 ", m.ename)
FROM emp e
LEFT OUTER JOIN emp m ON e.MGR = m.EMPNO;
CONCAT(e.ename, "의 매니저는 ", m.ename)|
-----------------------------------+
SMITH의 매니저는 FORD |
ALLEN의 매니저는 BLAKE |
WARD의 매니저는 BLAKE |
JONES의 매니저는 KING |
MARTIN의 매니저는 BLAKE |
BLAKE의 매니저는 KING |
CLARK의 매니저는 KING |
SCOTT의 매니저는 JONES |
|
TURNER의 매니저는 BLAKE |
ADAMS의 매니저는 SCOTT |
JAMES의 매니저는 BLAKE |
FORD의 매니저는 JONES |
MILLER의 매니저는 CLARK |
SELECT CONCAT(e.ename, "의 매니저는 ", m.ename)
FROM emp e
RIGHT OUTER JOIN emp m ON e.MGR = m.EMPNO;
CONCAT(e.ename, "의 매니저는 ", m.ename)|
-----------------------------------+
|
|
|
FORD의 매니저는 JONES |
SCOTT의 매니저는 JONES |
|
JAMES의 매니저는 BLAKE |
TURNER의 매니저는 BLAKE |
MARTIN의 매니저는 BLAKE |
WARD의 매니저는 BLAKE |
ALLEN의 매니저는 BLAKE |
MILLER의 매니저는 CLARK |
ADAMS의 매니저는 SCOTT |
CLARK의 매니저는 KING |
BLAKE의 매니저는 KING |
JONES의 매니저는 KING |
|
|
|
SMITH의 매니저는 FORD |
|
-- FULL OUTER JOIN --
SELECT CONCAT(e.ename, "의 매니저는 ", m.ename)
FROM emp e
LEFT JOIN emp m ON e.MGR = m.EMPNO
UNION ALL
SELECT CONCAT(e.ename, "의 매니저는 ", m.ename)
FROM emp e
RIGHT OUTER JOIN emp m ON e.MGR = m.EMPNO;
CONCAT(e.ename, "의 매니저는 ", m.ename)|
-----------------------------------+
SMITH의 매니저는 FORD |
ALLEN의 매니저는 BLAKE |
WARD의 매니저는 BLAKE |
JONES의 매니저는 KING |
MARTIN의 매니저는 BLAKE |
BLAKE의 매니저는 KING |
CLARK의 매니저는 KING |
SCOTT의 매니저는 JONES |
|
TURNER의 매니저는 BLAKE |
ADAMS의 매니저는 SCOTT |
JAMES의 매니저는 BLAKE |
FORD의 매니저는 JONES |
MILLER의 매니저는 CLARK |
|
|
|
FORD의 매니저는 JONES |
SCOTT의 매니저는 JONES |
|
JAMES의 매니저는 BLAKE |
TURNER의 매니저는 BLAKE |
MARTIN의 매니저는 BLAKE |
WARD의 매니저는 BLAKE |
ALLEN의 매니저는 BLAKE |
MILLER의 매니저는 CLARK |
ADAMS의 매니저는 SCOTT |
CLARK의 매니저는 KING |
BLAKE의 매니저는 KING |
JONES의 매니저는 KING |
|
|
|
SMITH의 매니저는 FORD |
|
SQL
복사
다중 조인
-- 사원(EMP) 테이블과 부서(DEPT) 테이블을 조인하여, 사원명, 부서번호, 부서명을 출력
-- 사원 테이블에는 부서번호 40번 데이터가 없지만, 40번 부서의 부서명도 함께 출력
select e.ENAME, e.DEPTNO, d.DNAME
from DEPT d
LEFT JOIN emp e USING (deptno);
ENAME |DEPTNO|DNAME |
------+------+----------+
CLARK | 10|ACCOUNTING|
KING | 10|ACCOUNTING|
MILLER| 10|ACCOUNTING|
SMITH | 20|RESEARCH |
JONES | 20|RESEARCH |
SCOTT | 20|RESEARCH |
ADAMS | 20|RESEARCH |
FORD | 20|RESEARCH |
ALLEN | 30|SALES |
WARD | 30|SALES |
MARTIN| 30|SALES |
BLAKE | 30|SALES |
TURNER| 30|SALES |
JAMES | 30|SALES |
| |OPERATIONS|
-- NEW YORK에서 근무하고 있는 사원에 대하여 사원명, 업무, 급여, 부서명을 출력
select * from emp e;
select e.ename, e.job, e.sal, d.dname
from emp e
JOIN dept d USING (deptno)
where d.loc = 'NEW YORK';
ename |job |sal |dname |
------+---------+------+----------+
CLARK |MANAGER |2450.0|ACCOUNTING|
KING |PRESIDENT|5000.0|ACCOUNTING|
MILLER|CLERK |1300.0|ACCOUNTING|
-- 보너스(comm)가 null 이 아닌 사원에 대하여 사원명, 부서명, 위치를 출력
select e.ename, d.dname, d.loc
FROM emp e
JOIN dept d USING (deptno)
WHERE e.comm is not null;
ename |dname|loc |
------+-----+-------+
ALLEN |SALES|CHICAGO|
WARD |SALES|CHICAGO|
MARTIN|SALES|CHICAGO|
TURNER|SALES|CHICAGO|
-- 사원명 중 L자가 있는 사원에 대하여 사원명, 업무, 부서명, 위치를 출력
select e.ename, e.job, d.DNAME, d.LOC from emp e
JOIN dept d USING (deptno)
WHERE e.ename LIKE '%L%';
ename |job |DNAME |LOC |
------+--------+----------+--------+
ALLEN |SALESMAN|SALES |CHICAGO |
BLAKE |MANAGER |SALES |CHICAGO |
CLARK |MANAGER |ACCOUNTING|NEW YORK|
MILLER|CLERK |ACCOUNTING|NEW YORK|
-- 자신의 관리자보다 먼저 입사한 사원에 대하여 이름, 입사일, 관리자 이름, 관리자 입사일을 출력
select * from emp;
select e.ename, e.hiredate, m.ename, m.hiredate from emp e
JOIN emp m ON e.mgr = m.empno
where e.hiredate < m.hiredate;
ename|hiredate |ename|hiredate |
-----+----------+-----+----------+
SMITH|1980-12-17|FORD |1981-12-03|
ALLEN|1981-02-20|BLAKE|1981-05-01|
WARD |1981-02-22|BLAKE|1981-05-01|
JONES|1981-04-02|KING |1981-11-17|
BLAKE|1981-05-01|KING |1981-11-17|
CLARK|1981-06-09|KING |1981-11-17|
SQL
복사
데이터 추가 - INSERT
•
INSERT INTO 뒤에 추가할 테이블을 입력하고,
행의 데이터는 VALUES 구를 사용해 작성한다.

•
INSERT문을 실행하면 처리상태만 표시되기 때문에
SELECT문을 이용해야 입력된 데이터를 직접 확인할 수 있다.
•
INSERT문은 저장할 열을 지정할 수 있다.
지정되지 않은 열은 기본값 또는 null이 저장된다.

INSERT INTO tCity (name, area, popu, metro, region) VALUES
('오산', 42, 21, 'n', '경기');
insert into tCity
values
("이천", 461, 21, 'n', '경기'),
("대구", 883, 248, 'y', '경상'),
("영월", 1127, 4, 'n', '강원')
insert into tcity
(select factory, 940, 83, 'n', '충청' from tmaker where maker = '쌍용');
select * from tCity tc ;
SQL
복사
DELETE
•
만약 where 구를 생략하게 되면 해당 테이블의 모든 데이터가 삭제된다.
따라서 DELETE 명령을 실행할 때는 주의를 기울여야 한다.

UPDATE
•
데이터 갱신 작업은 시스템을 다루는 과정에서 빈번히 발생한다. UPDATE 는 셀 단위로 데이터가 갱신된다. WHERE 구를 생략한 경우에는 테이블의 모든 행이 갱신된다.

•
갱신해야 할 열이 복수인 경우 콤마(,)로 구분하여 지정한다.

# UPDATE 테이블 SET
-- name 이 서울인 데이터의 popu 는 1000 으로 region 은 충청으로 수정
update tCity set popu = 1000, region = "충청" where name = '서울';
-- name 이 오산인 데이터의 popu 을 2배로 갱신
update tCity set popu = popu * 2 WHERE name = '오산';
-- 여자 사원 모두를 차장으로 갱신
select * from tStaff ts ;
select * from tStaff ts where gender = '여';
update tStaff set grade = '차장' where gender = '여';
-- 총무부 직원의 월급을 10% 인상
select * from tStaff ts where depart = "총무부"
update tStaff set salary = salary * 1.1 where depart = "총무부";
SQL
복사